In my first article Artificial Intelligence – What Is It Actually?, I discussed the individual subfields of AI and explained the differences between a normal program and an AI. This article now focuses on the algorithms that can lead from a weak AI to a strong AI. Using two simple examples and a brief excursion into the world of neural networks, I will provide a first impression of how such algorithms work.
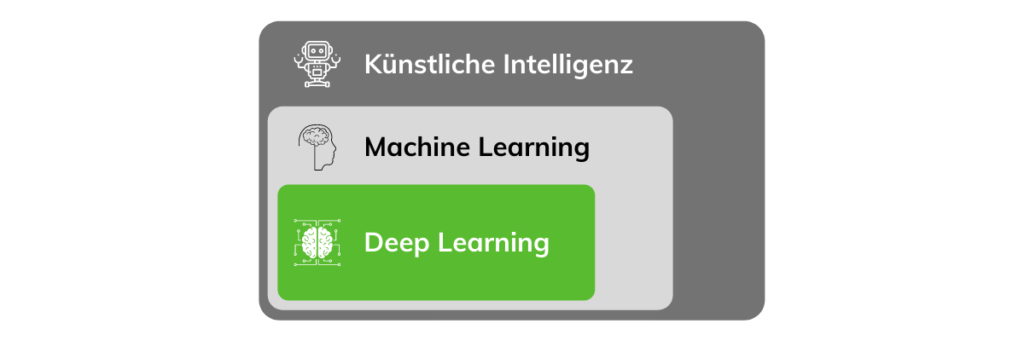
Distinguishing AI, Machine Learning, and Deep Learning
To progress from a weak AI to a strong AI, the machine must learn to think like a human. The techniques and processes used for this are summarized under Machine Learning, which in turn is a subfield of Artificial Intelligence. There are various ways this learning process can occur:
- Supervised Learning: Both the input and the correct output are available to the learner
- Reinforcement Learning: While the correct answer is not available, there is feedback in the form of rewards and punishments
- Unsupervised Learning: There is no indication of what the correct output is. A structure in the input can be learned using supervised learning methods by predicting future inputs based on past inputs
Another frequently used term in this context is “Deep Learning,” a subfield of machine learning. Deep Learning is a way to implement machine learning using neural networks.
Machine Learning Algorithms
Machine Learning is the creation of predictive models by finding connections in various datasets. For a Machine Learning algorithm to work well, it must first be trained using training data. This training data is searched for patterns and connections by the respective algorithm. Examples of machine learning include decision trees or clustering methods (such as K-Means), which are described in more detail below.
Establishing Hypotheses
Suppose we are given five data points in a diagram. Now we should find out what the function looks like that connects these points. In supervised learning, we are given the data points x and the corresponding function values f(x) as input. However, since our algorithm should learn, we need to establish a function (hypothesis) that tries to imitate the true function as best as possible. To illustrate, here are four different hypotheses shown:
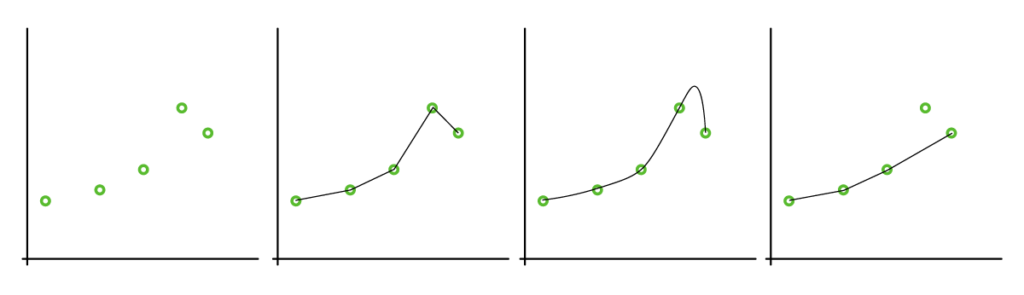
Now the question arises, which is the correct function? Since there are many different possibilities, we need assumptions that limit the search space, the so-called “bias”. Usually, we look for an approximation that is as simple as possible. This is also evident in the following method of decision trees.
Decision Tree
A decision tree is a supervised learning method. It describes a situation based on a set of characteristics. For simplicity, we consider a yes/no decision as the outcome.

This tree diagram describes the decision-making process of whether to enter a restaurant and possibly wait for a free table. The first decision depends on how many people are in the restaurant. If no one is there, the person doesn’t go in; if there are some people, the answer is yes; and if it’s full, it depends on the waiting time. The questions continue in this manner. It also depends on alternatives in the area, for example, how hungry the person is and whether it’s raining. Through positive and negative examples, the machine learning algorithm can create and refine a decision tree. When given a series of examples, some with a yes decision and some with a no decision, a decision tree must be found that determines the correct answer for the given examples. Thus, an algorithm for the decision tree is trained with these examples, so that the tree gives the correct answer as often as possible, i.e., has developed the correct hypothesis. The problem that exists in developing the algorithm for the decision tree is that with n different decision attributes, 2^(2^n) possible hypotheses can arise. To verify the decision tree, new unknown situations are given to the algorithm as input. These data are called test data. The algorithm is validated if it makes the correct decision.
K-Means
K-Means is a clustering method from the category of unsupervised learning. The algorithm works according to a fixed procedure:
- Choose K points as initial centers
- Calculate the distances of all points to the respective centers
- Assign the data points to the centers with the smallest distance
- Center the centers in the resulting cluster
- Repeat the process from point 2 until the centers no longer change
The following figure shows a run of the algorithm with 8 iteration steps:
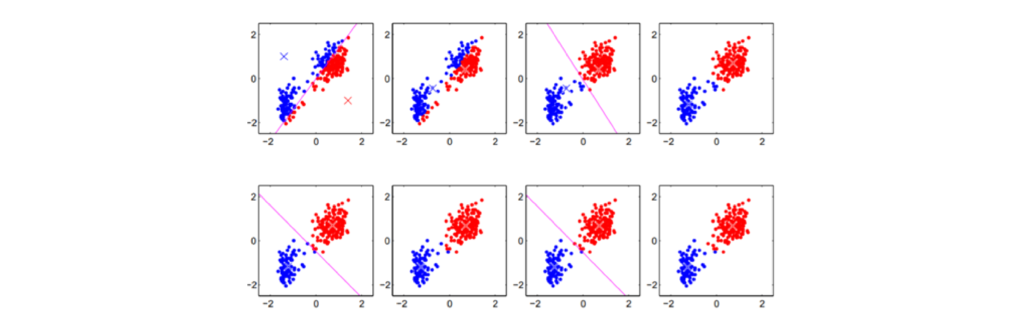
This algorithm can be used, for example, to cluster flowers. The stem length and flower color are chosen as criteria, and the flowers are plotted as data points in a coordinate system. By applying the algorithm multiple times, clusters are output depending on how many centers were initially chosen. In this case, each cluster corresponds to a flower species.
Deep Learning – Neural Networks
Neural networks are needed to realize more complex tasks. The aim is to artificially recreate the human brain.

Neural Networks – Structure of a Neuron
A neuron transmits an electrical signal from the dendrites along the axons to the terminals. These signals are then passed on to another neuron. This is how we perceive our environment. Neurons suppress their signals up to a certain point before they react. This means they must first exceed a threshold. Mathematically speaking, it is not possible to simulate a human brain with linear functions, as is possible with classification problems. A function is needed that takes an input signal and produces an output signal considering a threshold. This type of function is called an activation function. The sigmoid function y=1/(1+e^(-x)) is very well suited for this.

Deep Learning – Activation Function
The figure above shows how a neuron can be implemented mathematically. It receives multiple input values, which are summed up. The resulting sum goes as input into the sigmoid function, which controls the output. Since the human brain doesn’t consist of a single neuron, many of these artificial neurons are connected, resulting in the artificial neural network:
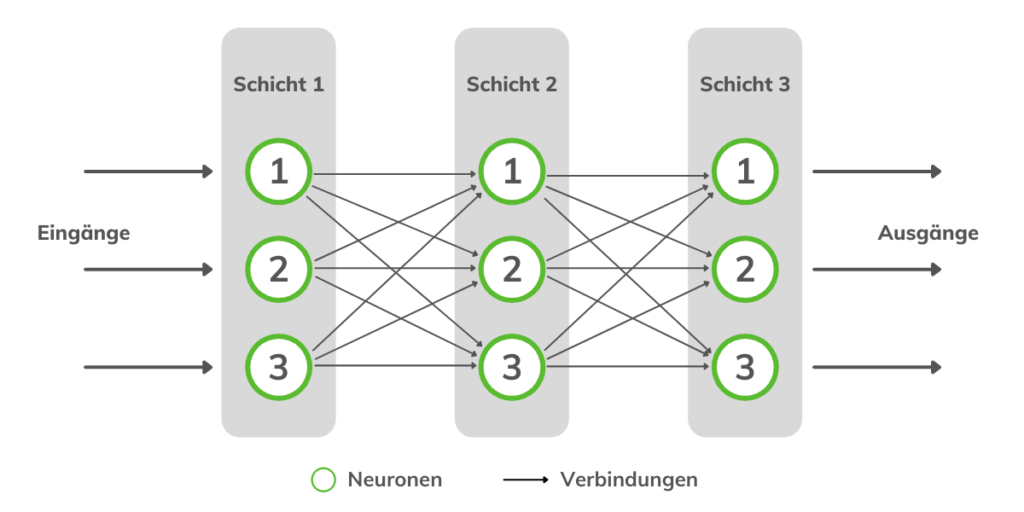
Now we have a construct that can solve difficult problems. But how does such a network learn? It’s obvious to vary the strength of the connections between individual neurons. This is done using weights on the individual connections.

In this example, each node is connected to every node in the next layer. This is not always necessary. Through the learning process, those connections that are not needed are set to 0 and are thus no longer relevant for the neural network.
There are different types of neural networks, such as the convolutional neural network, which is used in the field of image recognition, among others. Each individual layer here is responsible for identifying individual components of an image. For example, the first layer can filter out straight lines in an image, the second curves, and so on. All these parts are put together, and in the end, an image is recognized. Areas of application include, for example, automatic license plate recognition or the decoding of handwritten zip codes on letters.
Summary – How Does Artificial Intelligence Work?
Machine Learning is the basis for artificial intelligence. It consists of statistical prediction models that enable the machine to independently learn relationships without having them directly defined. This ranges from simple algorithms like clustering methods to complex mathematical constructs such as neural networks.

