
Operating one’s own server infrastructures is now considered outdated and only makes sense in special cases. In the course of digitalization, cloud providers took over server-side tasks, including management and scaling. As a result, companies outsource the costs for hardware acquisition or server software updates to cloud providers. This relieves them primarily financially.
The advantage for the cloud provider is that unused resources can easily be allocated to another customer. Lower electricity costs and bulk discounts on hardware purchases also reduce costs. According to the principle of utility computing, the customer only has to pay for actually used computing power and resources. How cloud providers make the desired resources available is usually not noticeable to the customer. Through intelligent load balancing, the cloud provider’s server networks can react to peak loads and add resources or shut down unused servers during low access periods, thus optimizing costs. High guaranteed availability and the ability to scale almost infinitely are just some of the advantages that a cloud solution brings.
In the following, the first step will be to explain Serverless Architecture as an overall concept in more detail. Then, the most common scaling methods used by cloud providers will be presented.
What Exactly is Serverless Architecture?
The term “Serverless” is translated into German as “serverlos”. This of course doesn’t mean that there are no physical servers anymore. It just means that developers can create and run applications without having to manage servers. Routine tasks such as management and especially scaling are taken over by the cloud provider. The code to be executed is packed by the developer into so-called containers, which are then executed by the server in the cloud. Once the containers are in the cloud, they are “triggered” via an event-driven execution model. Commonly used “triggers” are, for example, writing to a specific database table or a user logging in. The application can react to the event and execute the desired function of the application in the container. Containers can also act on demand and can thus be automatically scaled up or down as demand increases or decreases.
Billing is also based on the event-driven execution model. This means you don’t pay for the time the container is available, but for the number and duration of executions. This is possible because resources are dynamically allocated to the container only at the moment the event occurs. Thus, no costs are incurred when the container is not triggered.
Serverless solutions can be roughly divided into two subcategories: Backend-as-a-Service (BaaS) and Functions-as-a-Service (FaaS). However, the latter is usually meant when talking about classic serverless computing. They overlap to some extent because in both variants, the developer needs to pay little to no attention to hosting the backend. To combine the advantages of each category, most larger apps like Instagram use a hybrid form in their backend infrastructures.
Functions-as-a-Service
The classic serverless model is called Functions-as-a-Service and broadly describes the event-driven execution model explained above. Developers write server-side logic that runs in containers as soon as a specific event occurs. The logic is divided into individual functions, each performing a single action. The function can be started within milliseconds and immediately process requests. For multiple simultaneous requests, the function is automatically copied multiple times by the system. A use case for this would include batch processing of files or translating incoming texts into another language. FaaS is therefore always suitable when the application is stateless (or connected to a database) and/or when it has very irregular load peaks. FaaS also offers many advantages for asynchronous applications. Some popular providers for Cloud Functions are AWS Lambda, Azure Functions, and Firebase Cloud Functions.
Backend-as-a-Service
Unlike FaaS, BaaS is not event-driven. Functions can usually be called via APIs and are provided directly by the cloud provider. In this case, no server-side code needs to be written by the developer, but only called from the client-side application via APIs. Popular use cases are user authentication, using databases in the cloud, or using neural networks for machine learning algorithms.
A major difference lies in scaling. While applications used in the FaaS model can be easily replicated to serve load peaks, this is more complicated with BaaS. In some cases, manual scaling by the customer is required, specifically when the scaling logic deviates from classic container replication. Perhaps the best-known BaaS provider is Google Firebase, which has numerous functions such as authentication, cloud storage, real-time databases, etc. Other providers include AWS and Microsoft Azure.
How Do Serverless Applications Scale?
As early as the mid-1990s, John Young described the term scalability as follows: “The ability [of a system, editor’s note] to maintain the performance level when adding new processors”. This is still used as part of the definition today, but no longer describes all the characteristics of scalability.
In the IT industry today, a system is defined as scalable if it possesses the following capabilities:
1. The ability of a system or application to continue functioning even when changed in size or volume to meet the user’s changed requirements. It is scaled either on the product itself (e.g., RAM or CPU cores) or in a new context (e.g., a new operating system).
2. The ability not only to function in the newly scaled environment but also to derive added value from it. Possible benefits include, for example, that the system can serve more users simultaneously than before or that it can process requests from the same number of users faster.
What Role Does Elasticity Play?
Elasticity is often used as a synonym for scalability, but in practice, this is only partially true. While scalability generally reflects the definitions given above, i.e., the ability to dynamically adapt hardware resources to the load, elasticity ensures that load peaks are dynamically managed. It is thus the ability to adjust resources so that the customer pays for as few unused resources as possible. This ensures that, in the best case, the available resources exactly match the current requirements. The limits of available resources are set by elasticity, while scalability operates within these limits. Ideally, both move in a kind of synergy effect, as neither is particularly efficient alone. The effective use of scaling methods thus requires elasticity.
What Methods of Scaling Are There?
Scalability is implemented at the application level. Scalable systems use two methods to handle and process a growing amount of workloads: vertical and horizontal scaling.
Vertical Scaling
The first and most commonly used scaling method is called vertical scaling. Almost any application, given the appropriate cloud, can scale vertically to a limited extent. This is done either by transferring the application to a larger virtual machine or by allocating more computing capacity to the corresponding VM. By adding more CPU cores, larger disk storage, or increasing graphics memory, the application can thus serve a higher number of client requests simultaneously.
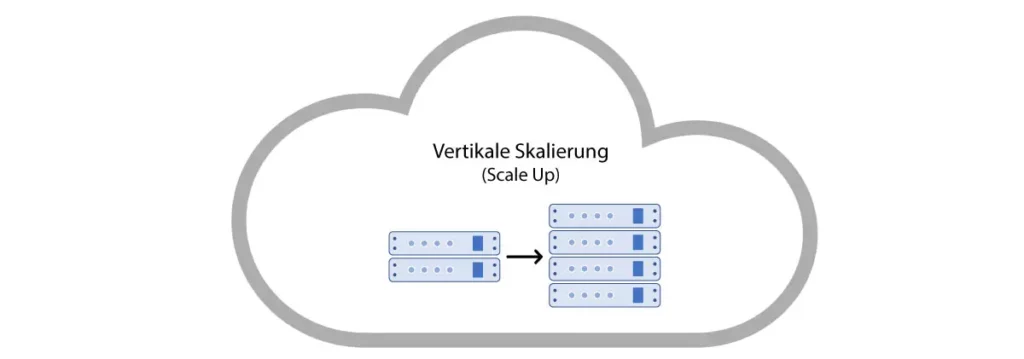
Vertical scaling often doesn’t need to be planned by the application developer, as most applications inherently support it. For example, with a REST API, the load balancer can automatically distribute incoming requests across available resources. A disadvantage of vertical scaling is the server downtime that must be waited out until the desired hardware is added or removed. Thus, vertical scaling methods always carry a higher risk of total failures.
Horizontal Scaling
Horizontal scaling, on the other hand, describes the addition of physical machines to the cluster. These can be additional servers, databases, etc. By increasing the number of nodes in the cluster, the load that each individual has to bear is reduced. This creates new endpoints for client requests.
Horizontal scaling is particularly suitable for event-based systems, as multiple instances of the same application can be easily created. For Functions-as-a-Service, cloud providers mostly rely on horizontal scaling. A new container is created for each event, which executes the corresponding function. If the capacity of a single node in the cluster is exhausted, additional ones are simply added to reduce the load for each individual. This principle allows applications to scale practically infinitely.
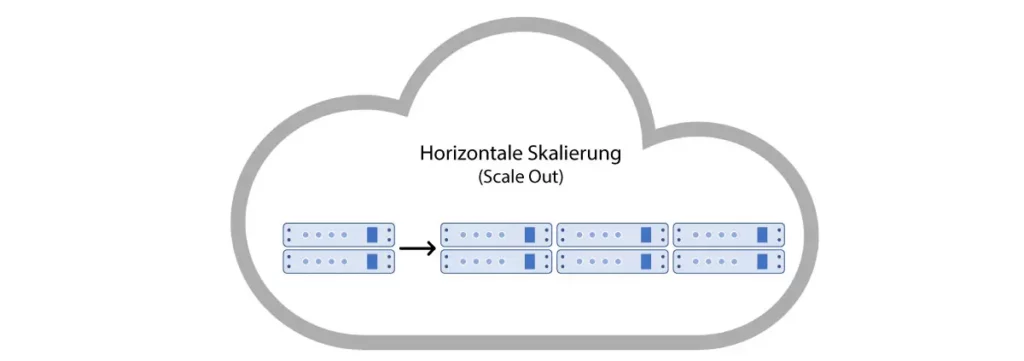
Traditional applications such as REST APIs have the disadvantage of requiring manual configuration effort to scale horizontally. Here, it must be regulated which request is forwarded to which node and how the load is generally distributed in the server cluster. Due to low cluster downtimes and rapid adaptation to load changes, many of the large internet companies and web services such as Google, Facebook, and Amazon rely on horizontal scaling, among other methods.
Conclusion
In conclusion, it must be emphasized once again that the described methods only represent a theoretical approach and none are implemented exactly as such in practice. Usually, mixed forms are used to align cloud infrastructures for maximum performance and efficiency and to minimize costs for the customer according to the pay-per-use principle.
The form most commonly used in reality could be termed diagonal scaling. It describes a mixed form of both methods. In practice, this means that new capacities are made available to a single server until its configuration no longer allows it. From then on, the server is physically replicated, meaning additional identical server instances are added to the server cluster.
In the next part of the article series, an example application in the cloud will be analyzed in terms of its scalability, considering factors such as effort and potential problems, with a further focus on costs as the number of users increases.
Sources used: HOSKIN, Fletcher J. s J. J. s J.: Exploring IBM’s New-Age Mainframes – ISBN 978–1885068156; Scalability; Elasticity[/artikel_text]

