
Choosing the Appropriate Machine Learning System for a Problem
Before employing Machine Learning, one should first consider what kind of problem needs to be solved. Since there are many different types of machine learning systems, it makes sense to categorize them into larger groups based on the following criteria:
Depending on whether a person should intervene in the learning process, the decision falls on a supervised, unsupervised, semi-supervised, or reinforcement learning approach.
Does the system model need to learn gradually or during ongoing operation (online vs. batch)?
Is it sufficient to simply compare new data points with known data points, or is it necessary to recognize patterns in the training data and create a predictive model (instance-based vs. model-based training)?
One of the most common tasks for Supervised Learning is classification, as used in the example of the spam filter. This learns continuously by using, for example, a deep neural network that is trained on examples. It is thus an online, model-based, supervised learning system. The spam filter is trained with many example emails and their corresponding classes to determine whether they are spam or ham. Through this, the spam filter’s model learns how to classify new emails.
Another typical task for Supervised Learning models is to predict specific numerical values, such as the price of a particular object. This prediction can be made through a so-called regression by providing a series of properties, also known as predictors. For a car price prediction, the following properties could be considered in the learning model: mileage, age, brand, model year. The quantity and quality of the training data usually have far more influence on the accuracy of the model than the selection and tuning of the algorithm. Therefore, a sufficient number of examples for the desired objects (e.g., cars) with their predictors and associated labels are needed to train the system well.
The Supervised Learning Workflow
The following graphic describes the process of supervised learning in practice.
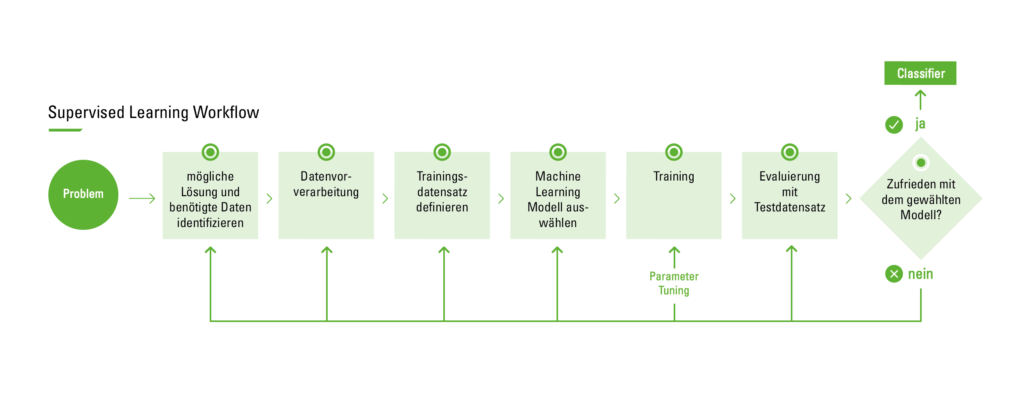
Supervised Learning Workflow
Before beginning the process, it’s first necessary to identify the problem in order to proceed with a suitable solution approach. Then, one begins with collecting the dataset. This may require the advice of an expert. They should assess which parameters have the greatest influence on the output and are thus most relevant. However, it won’t be possible to find a corresponding expert to assist in analyzing the properties to be imported for all cases. In this case, one can most easily resort to the so-called brute force method. In this context, it means analyzing all available data in hopes of isolating the right and relevant properties. However, a dataset collected using this method must be cleaned and preprocessed, as it often contains noise or missing property values. Noise refers to extreme outlier values that do not lie within the range of average cases and can thus distort the results of the algorithm.
The second step is data preparation and preprocessing. Various methods can be applied to handle missing data in the dataset, such as instance selection. It is used to deal with noise in data and to address the difficulty of learning from very large datasets by helping to remove irrelevant data. The fact that many features depend on each other often affects the accuracy of supervised learning classification models. This problem can be solved by developing new features from the basic feature set. This approach is called feature construction/transformation. The newly generated features can lead to more precise and accurate classifiers. As an example, imagine a list of people where some individuals have not provided their weight. To include these people, you could simply take the average of all weights and assign it to them. Moreover, discovering meaningful features contributes to a better understanding of the generated classifier and a better comprehension of the learned concept.
The next step is selecting the required learning algorithm. This step is the most critical. Once the model has been tested with the previously created test datasets and the result is satisfactory, the classifier is ready for final evaluation before routine use. The evaluation can be based on prediction accuracy, for example, which is the percentage of correct predictions divided by the total number of predictions. The following approaches can be used to calculate accuracy:
One approach is to split the training dataset, using two-thirds for training. The other third is used for the test set, where one tries to determine how well the algorithm performs with unknown inputs.
Another well-known technique is cross-validation. Here, the training dataset is divided into mutually exclusive, equal-sized subsets, and for each subset, the classifier is trained on the entirety of all other subsets. The average error rate of each subset is therefore an estimate of the classifier’s error rate.
If, after evaluating the model, it is determined that the error rate is unsatisfactory, one must return to the previous phase of the supervised learning workflow. Various factors then need to be investigated: Are irrelevant features being used for the problem? Is a larger training set needed? Is the dimensionality of the problem too high (are too many attributes being used)? Is the chosen algorithm unsuitable? Do the parameters need adjustment? Or is the dataset perhaps unbalanced?
How can the described workflow be applied to a real problem?
Use Case for Supervised Learning
For this use case, the problem is defined in the first step as forecasting a project. The next step is to begin collecting the dataset. For this, previous internal project forecasts are collected, which are already available in digatus’ own project management tool, as project managers document all relevant project information there. Additionally, the necessary features relevant for the forecast must be extracted and the dataset prepared. For this step, it is advisable to involve experienced project managers to learn which are the most important attributes of the dataset to pass on to the training model (e.g., number of employees, hourly rates, holidays, employee vacation patterns from previous years, etc.). This is followed by a particularly critical step, namely the selection of the machine learning model. Several models are available to choose from. Some examples of the most widely used models in supervised learning:
1) Support Vector Machines
2) Linear regression
3) Logistic regression
4) naive Bayes
5) decision trees
6) Random Forest
7) k-nearest neighbour algorithm
8) Neural Networks (Multilayer perceptron)
For this use case, the Random Forest approach is chosen. It is a composition of decision trees that can solve both regression and classification problems with large datasets. It also helps identify the most important variables from thousands of input variables. Random Forest is highly scalable for any number of dimensions and delivers quite acceptable performance. Finally, there are genetic algorithms that scale exceptionally well to any dimension and all data with minimal knowledge of the data itself, with the minimal and simplest implementation being the microbial genetic algorithm. However, with Random Forest, learning can be slow (depending on parameterization) and it is not possible to iteratively improve the generated models.
Now it’s time to train the dataset on the selected model. The training is followed by the testing phase. Based on the test result, it can be determined whether the outcome is acceptable or if the parameters need to be further adjusted to achieve better accuracy and a better result. It may also be necessary to select a different machine learning model.



