
A Functions-as-a-Service infrastructure that acts event-driven is used as a demo application. The implementation of the application could be realized with all major cloud providers. However, since Amazon Web Services is currently the market leader with approximately 33 percent market share of global cloud revenue, their cost calculator was used for calculating costs. For consistency, AWS services were also used for all functions in the application.
The demo application should upload images to the cloud and store them there. An image recognition algorithm should detect faces in the photos and analyze them, for example, for emotions. The information collected should then be stored in a database. In detail, the demo application should perform the following tasks:
- A client should be able to upload images to an AWS S3 File Bucket via an interface. All uploaded images should be permanently available there.
- As soon as an image is fully uploaded, an AWS Lambda function is triggered.
- The Lambda function now passes the image to the AWS Recognition API, which processes the image and searches for faces. If faces are found, they are analyzed and data such as the possible age of the person or emotions that this person is currently feeling can be queried.
- Once the Recognition API has completed image processing, it returns the collected data and triggers another Lambda function.
- The Lambda function now stores the collected data in an AWS DynamoDB, where it can then be queried. The further program flow is no longer relevant for the purposes of this article.

Image Upload Application (Source: AWS)
What initial effort is required to make the application scalable?
Since the cloud component consists of four independent services, each must be evaluated individually.
S3 File Bucket
AWS S3 File Storage offers automatic scaling methods without configuration effort. Unlike a server with partitions, S3 buckets can theoretically hold infinite amounts of bytes through virtualization. The distribution of redundant copies in case of data loss is also handled by AWS.
By categorizing files based on their access patterns into different storage classes, storage space is automatically saved. Files that are frequently requested are highly available. Less used files, on the other hand, are moved to cheaper storage classes.
An S3 object storage is thus capable of adapting to greatly changing amounts of files without manual configuration effort and can theoretically scale infinitely.
Lambda Functions
For each call of a Lambda function, AWS Lambda automatically creates a new instance of the function. This happens until the limit of the region in which the function is executed is reached. For an application from Germany, the data center in Frankfurt would automatically initialize up to 1000 parallel instances.
If this number is not sufficient to process incoming requests, AWS Lambda is able to start up to 500 additional instances per minute. This process continues until enough instances process the requests, or a preset concurrency limit is reached. This limit must be set manually by the user.
Once a peak load is overcome, unused instances are automatically shut down again.
Image Recognition
The AWS Image Recognition API is provided by AWS and can be called directly from Lambda functions. Therefore, it is not necessary to create a separate instance for each application. Scaling is also handled by AWS and does not fall within the end user’s responsibilities.
DynamoDB
AWS DynamoDB uses the AWS Application Auto Scaling Service to adjust throughput capacity to current usage patterns. This automatically increases throughput capacity when demand rises and automatically decreases it when demand falls.
The Auto Scaling Service includes a target utilization. This describes the percentage of consumed throughput at a given time. The value can be manually overridden to change target utilization values for read or write capacities, for example. The Auto Scaling Service will then attempt to adjust the actual capacity utilization to match the specified one. However, this only makes sense if load peaks can be roughly predicted.
In the case of the image processing application, you should not manually change the DynamoDB settings, as it automatically adapts to changing requirements here.
Speed and Availability
What happens in the case of a strong increase in load, and how quickly can the individual services of the application react to load peaks? Can performance losses be expected with rapid scaling?
S3 File Bucket
Since the structure of AWS S3 Simple Storage resembles a large distributed system rather than a single network endpoint, it makes no difference how many requests it has to process when used correctly. As there is no limit to the number of simultaneous connections, the bandwidth of the service can be maximized through an increased number of requests. However, if no additional connections are established, but a single connection is more heavily utilized, speed losses must be expected.
Lambda Functions
The scaling method of AWS Lambda Functions was already explained in the previous section. Fundamentally, it can be stated that it makes no difference for Lambda Functions as long as the number of simultaneous instances is below the regional limit (1000 in Germany). This limit can be increased by request in the AWS Support Center Console.
When processing a request for the first time from a newly created instance, the duration of code initialization must always be taken into account. This means that a newly created instance of a function that has not yet been used always takes longer to process a task than one that has already been used. With rapid scaling, a delay must therefore be expected.
If you want to avoid these described fluctuations in latency, you can use the so-called Provisioned Concurrency. The following figure illustrates this.
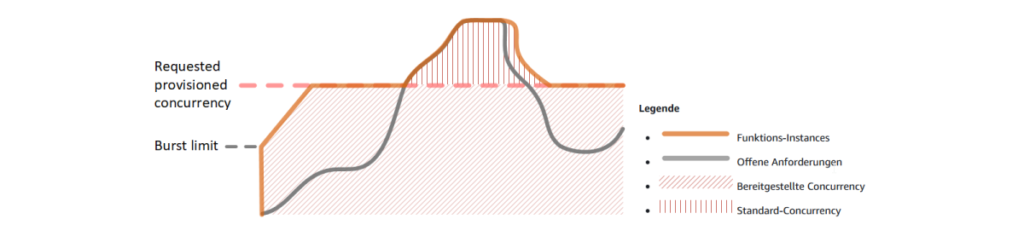
Function Scaling with Provisioned Concurrency (Source: AWS)
It is evident that up to the pink line (the configured number of provisioned concurrency), the number of available function instances is always greater than the number of open requests. The open requests can therefore be processed without delay. Only when the limit is exceeded are new instances started, and increased latency must be expected again.
Image Recognition
Since AWS Image Recognition is a service provided by AWS that is only called via API, there is no difference in speed or availability. Occurring load peaks are simply absorbed; the end user does not need to configure anything.
DynamoDB
When creating an AWS DynamoDB, the Auto Scaling Service is automatically active if it is not manually turned off. The general functioning of the Auto Scaling Service was already explained in the previous chapter.
If the values of the service are not overwritten, it automatically scales up the database’s throughput capacities if the target throughput is too high over a period of two minutes. If the throughput is lower than the desired target throughput for more than 15 minutes, the throughput capacities are automatically reduced. The following figure shows the consumed (blue) and provisioned (red) throughput capacity of the database over a period of 24 hours.

Consumed and provisioned read capacity
If the target throughput is not set too high, the database can respond to all requests efficiently and without performance losses. The space between the blue and red lines represents the free throughput capacity of the database. As soon as the blue line exceeds the red line too often, one should increase the target throughput. Normally, however, the Auto Scaling Service can react efficiently to all load peaks and no performance losses are to be expected.
How Can the Costs of the Application Be Calculated?
The starting value for calculating the fictitious costs of the application is 1000 executions. This is then multiplied by a factor of 10, with the last value being 100,000,000 executions. The fact that such a high value is probably rather rare in reality can be neglected for the purpose of cost development at this point. Subsequently, the costs for each service are calculated individually in order to distinguish different cost developments. Finally, an overview of the total costs of the application is provided. All prices were calculated using the AWS Cost Calculator.
S3 File Bucket
For S3 storage, three cost points must be distinguished. First, the used storage space is billed, and additionally, costs are incurred for each PUT and GET access to a file. When using the application, the file is uploaded exactly once and read out once again in each execution. For the following values, an average value of 5 MB per photo was used, which corresponds to a photo from a 15-megapixel camera for a high-resolution JPEG image.
| 1000/5 GB | 100,000/5 TB | 1 Mil./50 TB | 10 Mil./500 TB | 100 Mil./5 PB | |
| Storage | 0,1225 | 122,5 | 1225 | 11.750 | 112.500 |
| PUT Request | 0,0054 | 0,54 | 5,4 | 54 | 540 |
| GET Request | 0,00043 | 0,043 | 0,43 | 4,3 | 43 |
| Total | $0.12833 | $123.083 | $1230.83 | $11,808 | $113,083 |
Table: Cost development of AWS S3 storage in USD in relation to the number of files and used storage
The table shows that access to the files plays a minor role in costs, as they scale linearly up to 100 million calls. The used storage space consumes significantly more costs. It is noticeable that its prices are only slightly reduced from 50 terabytes of used storage onwards; before that, this value also scales linearly.
Lambda Functions
Lambda functions are used exactly twice per run in the application. Once when a file is finished uploading and once when the call to the AWS Recognition API is completed. The following values were used for the cost calculation.
| Memory | Duration per Execution | |
| Function 1 | 512 MB | 200 ms |
| Function 2 | 512 MB | 400 ms |
Table: Resource consumption of Lambda functions
Calculating the costs with the above values for increasing execution numbers yields the following results.
| ≤< 1 Mil. | 10 Mil. | 100 Mil. | |
| Function 1 | 0 | 11.8 | 179.8 |
| Function 2 | 0 | 28.47 | 346.47 |
| Total | $0 | $40.27 | $526.27 |
Table: Cost development of Lambda functions with increasing execution numbers
If the number of executions remains below 1 million, the service is completely free of charge. It is noticeable that with increasing execution numbers, the price does not decrease but slightly increases. At 100 million executions of the first function, the price per execution is about 60 percent more expensive than at only 10 million executions.
Image Recognition
The call to the Image Recognition API costs $0.001 per image up to a number of 1 million images. Only after a number of more than one million processed images does the price slowly decrease. The further cost development can be seen in the following table.
| 1000 | 100,000 | 1 Mil. | 10 Mil. | 100 Mil. | |
| Total | $1.2 | $120 | $1,200 | $8,000 | $60,000 |
Table: Cost development of the AWS Recognition Service with increasing execution numbers
DynamoDB
When calculating the costs for DynamoDB, multiple cost factors must be considered, similar to S3 storage. In addition to data storage costs, fees are also charged per write operation. These amount to $0.152 per 1000 records. For the following calculation, it was assumed that a record contains approximately 100 KB of data. This results in storage costs of $3.06 for 100,000 records. Both prices scale linearly upwards and do not deviate.
Total Costs
Finally, the development of the total costs is now considered. For this purpose, the total costs of the individual services were added. The following values were obtained:
| 1.000 | 10.000 | 100.000 | 1 Million | 10 Million | 100 Million | |
| Sum | $1.48 | $25.81 | $261.39 | $2,613.93 | $21,679.57 | $191,919.27 |
Table: Total cost development with increasing number of executions. For a better assessment of the development, a logarithmic scale was used in the following diagram.

Total Cost Development with Increasing Number of Executions
The X-axis shows the number of function executions, while the Y-axis shows the costs for the respective number of executions. At first glance, the costs scale almost linearly up to the final execution count of 100 million. Here, the costs amount to approximately $191,919. Looking at the individual values more closely, one can see that up to 100,000 executions, the cost per execution slightly increases and only then begins to decrease slightly.
Contrary to expectations that costs would be significantly reduced percentage-wise with a higher number of executions, the progression is almost linear and it doesn’t make much difference how often the function is executed.
Potential Difficulties and How to Avoid Them
With every cloud application, problems and difficulties can arise that one should be aware of to avoid surprises. Two of the most common ones are explained below.
Setting Limits
To avoid unnecessary costs, it is advisable to set limits for upper and lower thresholds. This could be, for example, a maximum number of Lambda executions per minute or a limit for S3 storage.
This can prevent costs from rising exponentially due to programming errors (e.g., unintended recursion) or server attacks. This problem doesn’t exist on your own servers, as the server would simply crash with too much data traffic. In the cloud, however, the application theoretically has the ability to allocate infinite resources. If one of the Lambda functions were to call itself in a certain case, AWS would start new instances without limit. The result would be a very high bill.
Execution/Cold Start Latency
Cold Start Latency describes the delay that a cloud provider needs to start the container that executes the desired function. This delay can range from a few milliseconds to several seconds and can make the application appear slow. A cold start occurs whenever a new container needs to be started because no other one is currently available. This happens especially when the application hasn’t been used for an extended period. The cold start latency can be reduced by minimizing the initialization code of the Lambda function or by manually ‘warming up’ the function at specific time intervals.
Conclusion and Outlook
It is apparent that the scaling of Serverless Architecture works very well in most cases without manual configuration effort. In the case of the AWS Cloud, the sample application can scale automatically. Only those who want to maximize performance and cost savings to 100 percent should manually change settings. However, one should be very well informed about the exact effects of changes. For example, reserved concurrency can be booked for Lambda functions for increased performance. However, this is associated with a significant increase in costs.
Serverless Architecture provides a good foundation for many business applications. This is mainly due to the high scalability and availability. It is also significantly cheaper than renting classic servers with the pay-per-use model. Another advantage is the faster ‘time-to-market’. Companies can focus more on their own product and spend less time maintaining, setting up, and monitoring server hardware.
In the future, major cloud providers with their serverless architecture will most likely completely displace the traditional data center from the market. The only disadvantage that many companies still criticize about serverless computing is a loss of control over the data. Once the data is on the cloud provider’s server, it becomes difficult for the end user to make changes. This is particularly problematic from the perspective of European companies, as the headquarters of the largest cloud providers are almost exclusively located in the USA and are therefore not bound by the European General Data Protection Regulation. However, if this point of criticism is also resolved, nothing will stand in the way of the future of serverless architecture and cloud computing.
Sources used: AWS, Medium, dynamoDB auto scaling

