
Als Demo-Applikation wird eine Functions-as-a-Service Infrastruktur verwendet, die ereignisgesteuert agiert. Die Implementierung der Applikation könnte mit allen größeren Cloud-Anbietern umgesetzt werden. Da Amazon Web Services aber momentan Marktführer mit ca. 33 Prozent Marktanteil am weltweiten Cloudumsatz ist, wurde für die Berechnung der Kosten deren Kostenkalkulator verwendet. Auch für alle verwendeten Funktionen in der Applikation wurden aus Gründen der Einheitlichkeit Services von AWS benutzt.
Die Demo-Applikation soll Bilder in die Cloud laden und dort speichern. Ein Algorithmus zur Bilderkennung soll in den Fotos Gesichter erkennen und diese zum Beispiel auf Emotionen hin analysieren. Die so gesammelten Informationen sollen anschließend in einer Datenbank gespeichert werden. Im Detail soll die Demo-Applikation also folgende Aufgaben erfüllen:
- Ein Client soll über eine Schnittstelle Bilder in ein AWS S3 File Bucket laden können. Dort sollen alle hochgeladenen Bilder dauerhaft verfügbar sein.
- Sobald ein Bild fertig hochgeladen ist, wird eine AWS Lambda-Funktion getriggert.
- Die Lambda-Funktion übergibt nun das Bild an die AWS Recognition API, die das Bild verarbeitet und nach Gesichtern sucht. Werden Gesichter gefunden, so werden diese analysiert und es können unter anderem Daten abgefragt werden, wie das mögliche Alter der Person oder Emotionen, die diese Person gerade empfindet.
- Sobald die Recognition API die Bildverarbeitung abgeschlossen hat, gibt sie die gesammelten Daten zurück und triggert eine weitere Lambda-Funktion.
- Die Lambda-Funktion speichert nun die gesammelten Daten in einer AWS DynamoDB, wo sie dann abgefragt werden können. Der weitere Programmablauf spielt für die Zwecke dieses Artikels keine Rolle mehr.

Image Upload Application (Quelle: AWS)
Welcher Aufwand ist initial nötig, um die Anwendung skalierbar zu machen?
Da die Cloud-Komponente aus vier unabhängigen Services besteht, muss jeder davon einzeln beurteilt werden.
S3 File Bucket
Die AWS S3 File Storage bietet automatische Skalierungsmethoden ohne Konfigurationsaufwand. Im Gegensatz zu einem Server mit Partitionen können S3 Buckets über Virtualisierung theoretisch unendliche Mengen an Bytes aufnehmen. Auch die Verteilung von redundanten Kopien im Falle eines Datenverlustes wird von AWS übernommen.
Mit dem Kategorisieren von Dateien anhand ihrer Zugriffsmuster in verschiedene Speicherklassen wird außerdem automatisch Speicherplatz gespart. Dateien, die oft angefragt werden, sind hochverfügbar. Weniger benutzte Dateien hingegen werden in günstigere Speicherklassen verschoben.
Ein S3-Objektspeicher ist also ohne manuellen Konfigurationsaufwand in der Lage, sich stark ändernden Mengen von Dateien anzupassen und theoretisch bis ins Unendliche zu skalieren.
Lambda Functions
Für jeden Aufruf einer Lambda Funktion wird von AWS Lambda automatisch eine neue Instanz der Funktion erzeugt. Dies passiert so lange, bis das Limit der Region erreicht wird, in der die Funktion ausgeführt wird. Für eine Anwendung aus Deutschland würde das Rechenzentrum in Frankfurt automatisch bis zu 1000 parallele Instanzen initialisieren.
Reicht diese Anzahl für die Bearbeitung der eingehenden Anfragen nicht aus, so ist AWS Lambda in der Lage bis zu 500 weitere Instanzen pro Minute zu starten. Dieser Prozess wird so lange fortgesetzt bis genügend Instanzen die Anfragen abarbeiten, oder ein voreingestelltes Gleichzeitigkeitslimit erreicht ist. Dieses Limit muss vom Benutzer manuell eingestellt werden.
Ist eine Lastspitze überwunden, so werden nicht benutzte Instanzen automatisch wieder heruntergefahren.
Image Recognition
Die AWS Image Recognition API wird von AWS bereitgestellt und kann direkt aus Lambda Funktionen heraus aufgerufen werden. Es muss deshalb nicht für jede Anwendung eine eigene Instanz erstellt werden. Die Skalierung wird ebenfalls von AWS übernommen und fällt nicht in den Aufgabenbereich des Endnutzers.
DynamoDB
AWS DynamoDB verwendet den AWS Application Auto Scaling Service, um die Durchsatzkapazität an die aktuellen Nutzungsmuster anzupassen. So wird die Durchsatzkapazität bei steigender Nachfrage automatisch erhöht und bei fallender Nachfrage automatisch gesenkt.
Der Auto Scaling Service enthält eine Zielauslastung. Diese beschreibt den Prozentsatz des verbrauchten Durchsatzes zu einem bestimmten Zeitpunkt. Der Wert kann manuell überschrieben werden, um z.B. Zielauslastungswerte für Lese- oder Schreibkapazitäten zu verändern. Der Auto Scaling Service wird daraufhin versuchen die tatsächliche Kapazitätsauslastung an die angegebene anzupassen. Dies macht aber nur Sinn, wenn ungefähr vorausgesagt werden kann, wann Lastspitzen auftreten.
Im Fall der Bildverarbeitungsanwendung sollte man die Einstellungen der DynamoDB aber nicht manuell verändern, da sie sich hier automatisch an sich ändernde Anforderungen anpasst.
Geschwindigkeit und Verfügbarkeit
Was passiert im Fall eines starken Lastanstiegs und wie schnell können die einzelnen Services der Anwendung auf Lastspitzen reagieren? Ist bei schneller Skalierung mit Leistungseinbußen zu rechnen?
S3 File Bucket
Da der Aufbau der AWS S3 Simple Storage einem großen verteilten System ähnelt und nicht einem einzelnen Netzwerkendpunkt, macht es bei korrekter Benutzung keinen Unterschied wie viele Anfragen es bearbeiten muss. Da keine Begrenzung für die Anzahl der gleichzeitigen Verbindungen existiert, kann über die eine erhöhte Anzahl der Anfragen die Bandbreite des Service maximiert werden. Werden hingegen keine zusätzlichen Verbindungen aufgebaut, sondern eine einzelne Verbindung stärker ausgereizt, so muss mit Geschwindigkeitseinbußen gerechnet werden.
Lambda Functions
Die Skalierungsweise von AWS Lambda Functions wurde bereits im vorherigen Abschnitt erklärt. Grundlegend lässt sich also feststellen, dass es für Lambda Functions keinen Unterschied macht, solange die Anzahl der gleichzeitigen Instanzen unter dem regionalen Limit liegt (in Deutschland bei 1000). Dieses Limit kann per Anfrage in der AWS Support Center Konsole erhöht werden.
Beim ersten Bearbeiten einer Anforderung von einer neu erstellten Instanz muss immer die Dauer der Codeinitialisierung mit einberechnet werden. Dies bedeutet, dass eine neu erstellte Instanz einer Funktion, die noch nicht verwendet wurde, immer länger für die Abarbeitung einer Aufgabe braucht, als eine bereits verwendete. Bei schneller Skalierung muss also mit einer Verzögerung gerechnet werden.
Möchte man diese beschriebenen Schwankungen in der Latenz umgehen, so kann die sogenannte bereitgestellte Parallelität (Provisioned Concurrency) verwendet werden. Die folgende Abbildung macht dies deutlich.
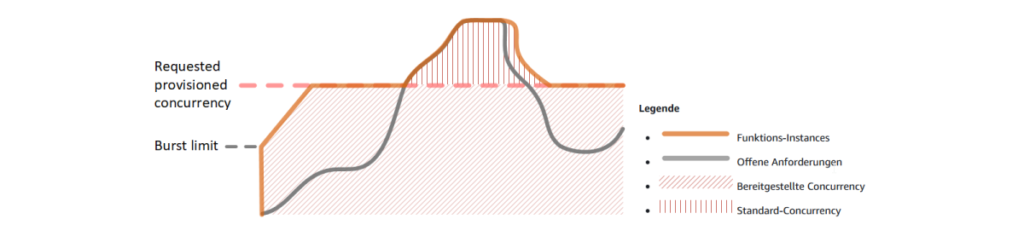
„Function Scaling with Provisioned Concurrency (Quelle: AWS)
Es ist ersichtlich, dass bis zum Erreichen der pinken Linie (die konfigurierte Anzahl an bereitgestellter Parallelität) die Anzahl der verfügbaren Funktionsinstanzen immer größer ist als die Anzahl der offenen Anforderungen. Die offenen Anforderungen können also ohne Verzögerung bearbeitet werden. Erst wenn die Grenze überschritten wird, werden neue Instanzen gestartet und es muss wieder mit erhöhter Latenz gerechnet werden.
Image Recognition
Da AWS Image Recognition ein von AWS bereitgestellter Service ist, der nur per API aufgerufen wird, gibt es keinen Unterschied in der Geschwindigkeit oder der Verfügbarkeit. Auftretende Lastspitzen werden einfach abgefangen, vom Endnutzer muss nichts konfiguriert werden.
DynamoDB
Beim Erstellen einer AWS DynamoDB ist der Auto Scaling Service automatisch aktiv, wenn er nicht manuell ausgeschaltet wird. Im vorherigen Kapitel wurde die grobe Funktionsweise des Auto Scaling Service bereits erläutert.
Werden die Werte des Service nicht überschrieben, so skaliert er die Durchsatzkapazitäten der Datenbank automatisch nach oben, wenn über einen Zeitraum von zwei Minuten der Zieldurchsatz zu hoch ist. Ist der Durchsatz über 15 Minuten hinaus niedriger als der gewünschte Zieldurchsatz, so werden die Durchsatzkapazitäten automatisch verringert. In der folgenden Abbildung ist die konsumierte (blau) und die bereitgestellte (rot) Durchsatzkapazität der Datenbank über einen Zeitraum von 24 Stunden zu sehen.

Consumed and provisioned read capacity
Ist der Zieldurchsatz nicht zu hoch gewählt, so kann die Datenbank alle Anfragen performant und ohne Leistungseinbußen beantworten. Der Raum zwischen der blauen und der roten Linie stellt hierbei die freie Durchsatzkapazität der Datenbank dar. Sobald die blaue Linie die rote Linie zu oft übersteigt, sollte man den Zieldurchsatz erhöhen. Im Normalfall kann der Auto Scaling Service aber auf alle Lastspitzen performant reagieren und es sind keine Leistungseinbußen zu erwarten.
Wie lassen sich die Kosten der Applikation berechnen?
Der Startwert zur Berechnung der fiktiven Kosten der Applikation liegt bei 1000 Durchführungen. Dieser wird dann jeweils mit dem Faktor 10 multipliziert, der letzte Wert liegt bei 100.000.000 Durchführungen. Dass ein so hoher Wert in der Realität vermutlich eher selten vorkommt, ist für den Zweck der Kostenentwicklung an dieser Stelle zu vernachlässigen. Im Anschluss werden die Kosten für jeden Service einzeln berechnet, um unterschiedliche Kostenentwicklungen unterscheiden zu können. Abschließend wird ein Überblick über die Gesamtkosten der Applikation gegeben. Die Preise wurden alle über den AWS-Kostenkalkulator berechnet.
S3 File Bucket
Beim S3 Speicher muss zwischen drei Kostenpunkten unterschieden werden. Einmal wird der verbrauchte Speicherplatz abgerechnet und zusätzlich fallen Kosten pro PUT und GET-Zugriff auf eine Datei an. Bei Benutzung der Applikation wird in jeder Durchführung die Datei genau einmal hochgeladen und einmal wieder ausgelesen. Bei den folgenden Werten wurde ein Durchschnittswert von 5 MB pro Foto verwendet, was bei einem hochauflösenden JPEG-Bild einem Foto von einer 15 Megapixel-Kamera entspricht.
| 1000/5 GB | 100.000/5 TB | 1 Mio./50 TB | 10 Mio./500 TB | 100 Mio./5 PB | |
| Speicher | 0,1225 | 122,5 | 1225 | 11.750 | 112.500 |
| PUT Request | 0,0054 | 0,54 | 5,4 | 54 | 540 |
| GET Request | 0,00043 | 0,043 | 0,43 | 4,3 | 43 |
| Summe | 0,12833 $ | 123,083 $ | 1230,83 $ | 11.808 $ | 113.083 $ |
Tabelle: Kostenentwicklung des AWS S3 Speichers in USD im Verhältnis zur Anzahl der Dateien und des verbrauchten Speichers
Der Tabelle ist zu entnehmen, dass die Zugriffe auf die Dateien eine untergeordnete Rolle bei den Kosten spielen, da sie bis zu 100 Mio. Aufrufen linear skalieren. Der verwendete Speicherplatz verbraucht deutlich mehr Kosten. Es fällt auf, dass auch dessen Preise erst ab 50 Terabyte verbrauchtem Speicher leicht reduziert werden, davor skaliert auch dieser Wert linear.
Lambda Functions
Lambda-Funktionen werden in der Applikation pro Durchlauf genau zweimal verwendet. Einmal, wenn eine Datei fertig hochgeladen wird und einmal, wenn der Aufruf an die AWS Recognition API beendet ist. Für die Berechnung der Kosten wurden folgende Werte verwendet.
| Arbeitsspeicher | Dauer pro Ausführung | |
| Funktion 1 | 512 MB | 200 ms |
| Funktion 2 | 512 MB | 400 ms |
Tabelle: Ressourcenverbrauch der Lambda-Funktionen
Berechnet man nun mit obigen Werten die Kosten bei steigenden Ausführungszahlen, so erhält man die folgenden Ergebnisse.
| =< 1 Mio. | 10 Mio. | 100 Mio. | |
| Funktion 1 | 0 | 11,8 | 179,8 |
| Funktion 2 | 0 | 28,47 | 346,47 |
| Summe | 0 $ | 40,27 $ | 526,27 $ |
Tabelle: Kostenentwicklung der Lambda-Funktionen bei steigender Ausführungszahl
Bleibt die Anzahl der Ausführungen unter 1 Mio., so ist der Service komplett kostenfrei. Auffällig ist, dass bei steigenden Ausführungszahlen der Preis nicht sinkt, sondern leicht steigt. Bei 100 Mio. Ausführungen der ersten Funktion ist der Preis pro Ausführung ca. 60 Prozent teurer als bei nur 10. Mio. Ausführungen.
Image Recognition
Der Aufruf der Image Recognition API kostet bis zu einer Anzahl von 1 Mio. Bilder 0,001 USD pro Bild. Erst ab einer Anzahl über einer Million verarbeiteter Bilder sinkt der Preis langsam. Die weitere Kostenentwicklung ist der folgenden Tabelle zu entnehmen.
| 1000 | 100.000 | 1 Mio. | 10 Mio. | 100 Mio. | |
| Summe | 1,2 $ | 120 $ | 1.200 $ | 8.000 $ | 60.000 $ |
Tabelle: Kostenentwicklung des AWS Recognition Service bei steigender Ausführungszahl
DynamoDB
Bei der Berechnung der Kosten für die DynamoDB müssen analog zum S3 Speicher mehrere Kostenfaktoren berücksichtigt werden. Neben den Kosten für die Datenhaltung werden pro Schreibvorgang ebenfalls Gebühren erhoben. Diese betragen 0,152 USD pro 1000 Datensätze. Für die folgende Berechnung wurde angenommen, dass ein Datensatz ca. 100 KB an Daten enthält. So ergeben sich Speicherkosten in Höhe von 3,06 USD für 100.000 Datensätze. Beide Preise skalieren linear nach oben und weichen nicht ab.
Gesamtkosten
Abschließend wird nun die Entwicklung der Gesamtkosten betrachtet. Hierzu wurden die Gesamtkosten der einzelnen Services addiert. Herausgekommen sind die folgenden Werte:
| 1.000 | 10.000 | 100.000 | 1 Mio. | 10 Mio. | 100 Mio. | |
| Summe | 1,48 $ | 25,81 $ | 261,39 $ | 2.613,93 $ | 21.679,57 $ | 191.919,27 $ |
Tabelle: Gesamtkostenentwicklung bei steigender Ausführungszahl. Für eine bessere Beurteilung der Entwicklung wurde im folgenden Diagramm eine logarithmische Skala verwendet.

Gesamtkostenentwicklung bei steigender Ausführungszahl
Auf der X-Achse ist die Anzahl der Funktionsausführungen abgebildet, auf der Y-Achse die Kosten für die jeweilige Anzahl der Ausführungen. Auf den ersten Blick skalieren die Kosten fast linear bis zur finalen Ausführungsanzahl von 100 Millionen. Hier betragen die Kosten dann ca. 191,919 USD. Betrachtet man die einzelnen Werte genauer so erkannt man, dass bis zu einer Anzahl von 100.000 Ausführungen die Kosten pro Ausführung leicht ansteigen und erst danach wieder leicht sinken.
Entgegen den Erwartungen, dass bei höherer Ausführungsanzahl die Kosten prozentual stark gesenkt werden, ist der Verlauf fast linear und es macht keinen großen Unterschied wie oft die Funktion ausgeführt wird.
Mögliche Schwierigkeiten und wie sie sich vermeiden lassen
Bei jeder Cloud Applikation können Probleme und Schwierigkeiten auftreten, denen man sich bewusst sein sollte, um Überraschungen zu vermeiden. Im Folgenden werden zwei der häufigsten erläutert.
Setzen von Limits
Um unnötige Kosten zu vermeiden, empfiehlt es sich Limits für Ober- und Untergrenzen zu setzen. Dies kann z.B. eine maximale Anzahl an Lambdaausführungen pro Minute oder ein Limit für den S3 Speicher sein.
So kann verhindert werden, dass durch Programmierfehler (z.B. ungewollte Rekursion) oder Serverangriffe die Kosten exponentiell steigen. Dieses Problem hat man auf eigenen Servern nicht, da bei zu viel Datenverkehr der Server einfach abstürzen würde. In der Cloud aber hat die Anwendung theoretisch die Möglichkeit, unendlich viele Ressourcen zu allokieren. Falls eine der Lambda-Funktionen sich in einem bestimmten Fall selbst aufrufen würde, so würde AWS unbegrenzt neue Instanzen starten. Das Resultat wäre eine sehr hohe Rechnung.
Execution/Cold Start Latency
Cold Start Latency beschreibt die Verzögerung, die ein Cloud Provider benötigt, um den Container zu starten, der die gewünschte Funktion ausführt. Diese Verzögerung kann zwischen wenigen Millisekunden und mehreren Sekunden liegen und kann die Anwendung langsam wirken lassen. Ein Cold Start kommt also immer dann vor, wenn ein neuer Container gestartet werden muss, weil gerade kein anderer verfügbar ist. Dies geschieht vor allem dann, wenn die Anwendung über einen längeren Zeitraum nicht benutzt wurde. Die Cold Start Latency kann verringert werden, wenn der Initialisierungscode der Lambda-Funktion verkleinert wird oder wenn die Funktion manuell in einem bestimmten Zeitintervall ”aufgewärmt” wird.
Fazit und Ausblick
Es ist erkennbar, dass die Skalierung von Serverless Architecture in den meisten Fällen sehr gut ohne manuellen Konfigurationsaufwand funktioniert. Im Falle der AWS Cloud kann die Beispielanwendung automatisch skalieren. Nur wer Performance und Kostenersparnis zu 100 Prozent ausreizen möchte, sollte manuell Einstellungen verändern. Hierbei sollte man sich aber genauestens informieren, welche Auswirkungen Änderungen genau haben. So kann z.B. bei Lambda Funktionen eine reservierte Gleichzeitigkeit für erhöhte Performance gebucht werden. Dies ist allerdings mit einer deutlichen Steigerung der Kosten verbunden.
Für viele Businessapplikationen bietet Serverless Architecture eine gute Grundlage. Dies liegt vor allem an der hohen Skalierbarkeit und Verfügbarkeit. Ebenfalls ist es mit dem Pay-Per-Use Modell deutlich billiger als das Anmieten von klassischen Servern. Ein weiterer Vorteil ist die schnellere ”Time-To-Market”. Firmen können den Fokus mehr auf ihr eigenes Produkt legen und müssen sich weniger mit Warten, Aufsetzen und Überwachen von Server-Hardware beschäftigen.
In der Zukunft werden die großen Cloud Provider mit ihrer Serverless Architecture das klassische Rechenzentrum mit hoher Wahrscheinlichkeit komplett vom Markt verdrängen. Den einzigen Nachteil, den noch viele Firmen am Serverless Computing bemängeln, ist ein Kontrollverlust über die Daten. Liegen diese nämlich einmal auf dem Server des Cloud-Anbieters, so kann der Endnutzer daran nur schwer Änderungen vornehmen. Dies ist vor allem aus der Sicht europäischer Firmen ein Problem, da die Firmensitze der größten Cloud Anbieter fast ausschließlich in den USA liegen und sie deshalb nicht an die europäische Datenschutzgrundverordnung gebunden sind. Sollte aber auch dieser Kritikpunkt einmal bereinigt sein, so steht der Zukunft der Serverless Architecture und des Cloud Computing nichts mehr im Weg.
Verwendete Quellen: AWS, Medium, dynamoDB auto scaling

