Dans mon premier article Intelligence Artificielle – qu’est-ce que c’est exactement ?, j’ai abordé les différents sous-domaines de l’IA et expliqué les différences entre un programme normal et une IA. Cet article traite maintenant des algorithmes permettant de passer d’une IA faible à une IA forte. À cette fin, je donnerai une première impression du fonctionnement de ces algorithmes à l’aide de deux exemples simples et d’une brève incursion dans le monde des réseaux neuronaux.
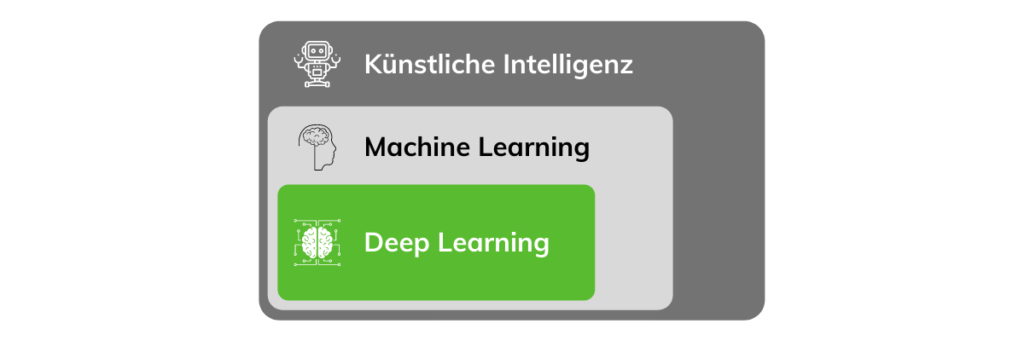
Délimitation entre IA, apprentissage automatique et apprentissage profond
Pour passer d’une IA faible à une IA forte, la machine doit apprendre à penser comme un être humain. Les techniques et processus utilisés à cette fin sont regroupés sous le terme d’apprentissage automatique, qui est à son tour un sous-domaine de l’Intelligence Artificielle. Il existe différentes manières dont ce processus d’apprentissage peut se dérouler :
- Apprentissage supervisé : Tant l’entrée que la sortie correcte sont disponibles pour l’apprenant
- Apprentissage par renforcement : Bien que la réponse correcte ne soit pas disponible, il y a un retour sous forme de récompenses et de punitions
- Apprentissage non supervisé : Il n’y a aucune indication sur ce que devrait être la sortie correcte. Une structure dans l’entrée peut être apprise à l’aide de méthodes d’apprentissage supervisé en prédisant les entrées futures sur la base des entrées passées
Un terme également très fréquemment utilisé dans ce contexte est l’« apprentissage profond », un sous-domaine de l’apprentissage automatique. L’apprentissage profond est une méthode de mise en œuvre de l’apprentissage automatique utilisant des réseaux neuronaux pour l’implémentation.
Algorithmes d’apprentissage automatique
L’apprentissage automatique consiste à créer des modèles prédictifs en trouvant des corrélations dans divers ensembles de données. Pour qu’un algorithme d’apprentissage automatique fonctionne bien, il doit d’abord être entraîné à l’aide de données d’entraînement. Ces données d’entraînement sont analysées par l’algorithme respectif à la recherche de motifs et de corrélations. Des exemples d’apprentissage automatique sont les arbres de décision ou les procédures de clustering (comme K-Means), qui seront décrits plus en détail ci-dessous.
Formulation d’hypothèses
Supposons que nous ayons cinq points de données donnés dans un diagramme. Nous devons maintenant déterminer à quoi ressemble la fonction qui relie ces points. Dans l’apprentissage supervisé, nous avons les points de données x et les valeurs de fonction correspondantes f(x) données en entrée. Cependant, comme notre algorithme doit apprendre, il s’agit d’établir une fonction (hypothèse) qui tente de reproduire la vraie fonction aussi bien que possible. Pour illustrer cela, voici quatre hypothèses différentes représentées :
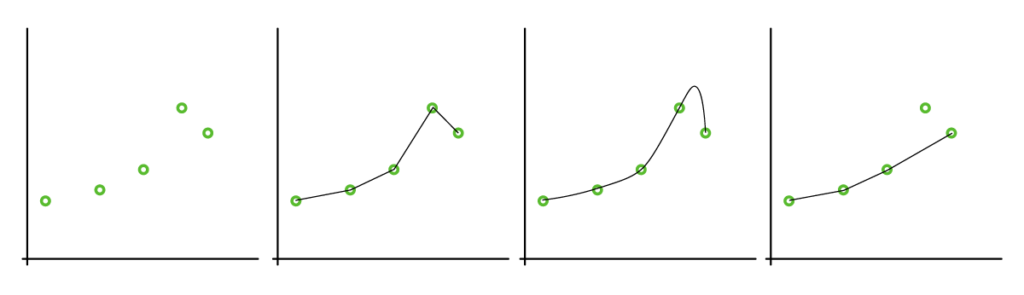
La question qui se pose maintenant est : quelle est la fonction correcte ? Comme il existe de nombreuses possibilités différentes, nous avons besoin d’hypothèses qui limitent l’espace de recherche, ce qu’on appelle le « biais ». La plupart du temps, nous recherchons une approximation qui soit aussi simple que possible. Ceci est également évident dans la méthode suivante des arbres de décision.
Arbre de décision
Un arbre de décision est une méthode d’apprentissage supervisé. Il décrit une situation à l’aide d’un ensemble de caractéristiques. Par souci de simplicité, nous considérons une décision oui/non comme résultat.

Ce diagramme arborescent décrit la question de savoir si l’on entre dans le restaurant et si l’on attend éventuellement une place libre. La première décision dépend du nombre de personnes présentes dans le restaurant. S’il n’y a personne, la personne n’entre pas non plus ; s’il y a quelques personnes dans le restaurant, la réponse est oui, et s’il est plein, cela dépend du temps d’attente. Les questions se poursuivent ainsi. Cela dépend également des alternatives dans les environs, par exemple de la faim de la personne et s’il pleut.
Grâce à des exemples positifs et négatifs, l’algorithme d’apprentissage automatique peut créer et affiner un arbre de décision. Lorsqu’une série d’exemples est donnée, certains avec une décision positive et d’autres avec une décision négative, il faut alors trouver un arbre de décision qui trouve la bonne réponse pour les exemples donnés. On entraîne donc un algorithme pour l’arbre de décision avec ces exemples, de sorte que l’arbre donne autant que possible toujours la bonne réponse, c’est-à-dire qu’il a développé la bonne hypothèse. Le problème qui se pose lors du développement de l’algorithme pour l’arbre de décision est que pour n attributs de décision différents, 2^(2^n) hypothèses possibles peuvent être générées.
Pour vérifier l’arbre de décision, de nouvelles situations inconnues sont données à l’algorithme en tant qu’entrée. Ces données sont appelées données de test. L’algorithme est validé s’il prend la bonne décision.
K-Moyennes
K-Moyennes est une méthode de clustering appartenant à la catégorie de l’apprentissage non supervisé. L’algorithme fonctionne selon une procédure fixe :
- Choisir K points comme centres initiaux
- Calculer les distances de tous les points à chaque centre
- Assigner les points de données aux centres les plus proches
- Centrer les centres dans le cluster résultant
- Répéter le processus à partir du point 2 jusqu’à ce que les centres ne changent plus
L’illustration suivante montre une exécution de l’algorithme en 8 étapes d’itération :
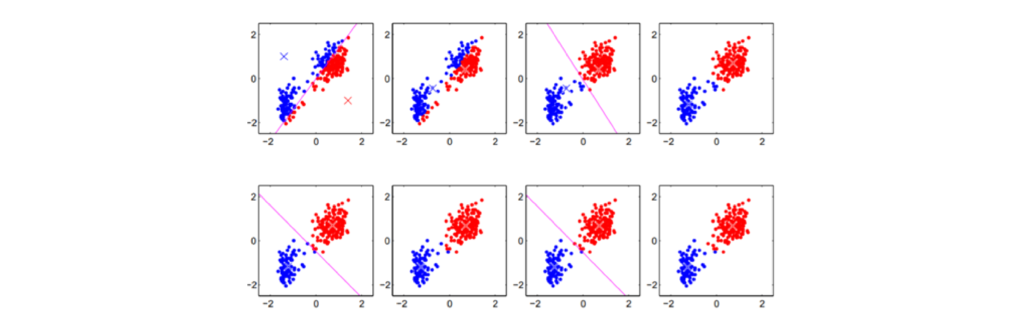
Cet algorithme peut être utilisé, par exemple, pour regrouper des fleurs. La longueur de la tige et la couleur de la fleur sont choisies comme critères et les fleurs sont tracées comme points de données dans un système de coordonnées. En appliquant l’algorithme plusieurs fois, des clusters sont générés en fonction du nombre de centres choisis au début. Dans ce cas, chaque cluster correspond à une espèce de fleur.
Apprentissage profond – Réseaux neuronaux
Les réseaux neuronaux sont nécessaires pour réaliser des tâches plus complexes. L’objectif est d’essayer de recréer artificiellement le cerveau humain.

Réseaux neuronaux – Structure d’un neurone
Un neurone transmet un signal électrique des dendrites le long des axones jusqu’aux terminaisons. Ces signaux sont ensuite transmis à un autre neurone. C’est ainsi que nous percevons notre environnement.
Les neurones suppriment leurs signaux jusqu’à un certain point avant de réagir. Cela signifie qu’ils doivent d’abord dépasser un seuil. D’un point de vue mathématique, cela signifie qu’il n’est pas possible de simuler un cerveau humain avec des fonctions linéaires, comme c’est le cas pour les problèmes de classification. Il faut une fonction qui prend un signal d’entrée et produit un signal de sortie en tenant compte d’un seuil. Ce type de fonction est appelé fonction d’activation. La fonction sigmoïde y=1/(1+e^(-x)) est très bien adaptée à cet effet.

Apprentissage profond – Fonction d’activation
Dans l’illustration ci-dessus, on peut voir comment un neurone peut être implémenté mathématiquement. Il reçoit plusieurs valeurs d’entrée qui sont additionnées. La somme résultante est utilisée comme entrée dans la fonction sigmoïde qui contrôle la sortie. Comme le cerveau humain n’est pas non plus composé d’un seul neurone, de nombreux neurones artificiels sont connectés, formant ainsi le réseau neuronal artificiel :
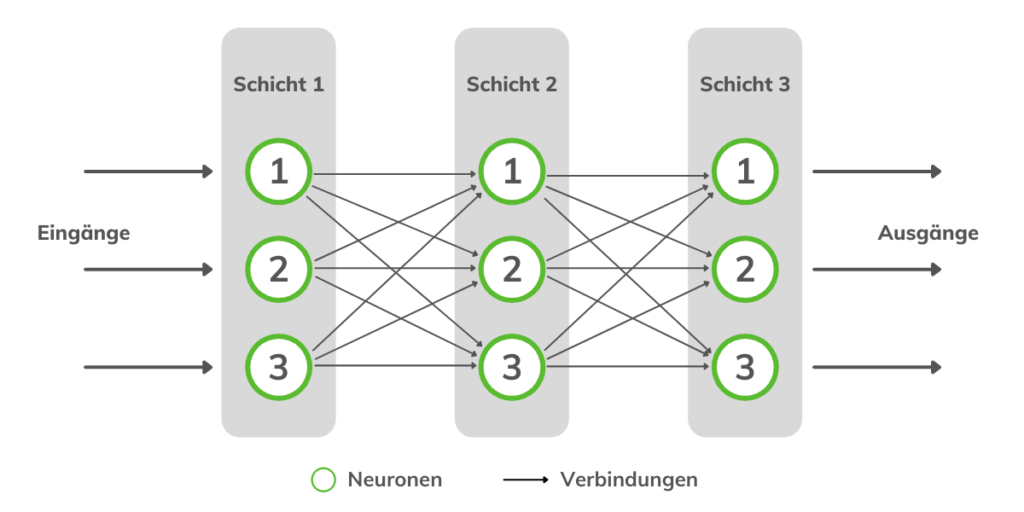
Nous avons maintenant une structure capable de résoudre des problèmes difficiles. Mais comment un tel réseau apprend-il ? Il est logique de faire varier la force des connexions entre les neurones individuels. Cela se fait à l’aide de poids sur les connexions individuelles.

Dans cet exemple, chaque nœud est connecté à chacun dans la couche suivante. Cela n’est pas toujours nécessaire. Au cours du processus d’apprentissage, les connexions qui ne sont pas nécessaires sont mises à 0 et ne sont donc plus pertinentes pour le réseau neuronal.
Il existe différents types de réseaux neuronaux, tels que le réseau neuronal convolutif, qui est utilisé, entre autres, dans le domaine de la reconnaissance d’images. Chaque couche individuelle est ici responsable de l’identification de composants individuels d’une image. Par exemple, la première couche peut filtrer les traits droits d’une image, la deuxième les courbes, et ainsi de suite. Toutes ces parties sont assemblées et, à la fin, une image est reconnue. Les domaines d’application comprennent, par exemple, la reconnaissance automatique des plaques d’immatriculation ou le décodage des codes postaux manuscrits sur les lettres.
Résumé – Comment fonctionne l’Intelligence Artificielle ?
L’apprentissage automatique est la base de l’intelligence artificielle. Il se compose de modèles de prédiction statistiques qui permettent à la machine d’apprendre indépendamment des relations sans qu’elles ne soient directement définies. Cela va des algorithmes simples comme les procédures de clustering aux constructions mathématiques complexes comme les réseaux neuronaux.

