
L’exploitation d’infrastructures de serveurs propres est désormais considérée comme obsolète et n’est pertinente que dans des cas spécifiques. Dans le cadre de la numérisation, les fournisseurs de cloud ont pris en charge les tâches côté serveur, y compris en ce qui concerne la gestion et la mise à l’échelle. Ainsi, les entreprises externalisent les coûts d’acquisition de matériel ou de mise à jour logicielle des serveurs aux fournisseurs de cloud. Elles sont donc principalement soulagées financièrement.
L’avantage pour le fournisseur de cloud réside dans le fait que les ressources inutilisées peuvent être simplement allouées à un autre client. De plus, des coûts d’électricité inférieurs et des remises quantitatives lors de l’acquisition de matériel réduisent les coûts encourus. Selon le principe de l’informatique utilitaire, le client ne paie ainsi que pour la puissance de calcul et les ressources effectivement consommées. La manière dont les fournisseurs de cloud mettent à disposition les ressources souhaitées n’est généralement pas perceptible par le client. Grâce à un équilibrage de charge intelligent, les réseaux de serveurs du fournisseur de cloud peuvent réagir aux pics de charge et ajouter des ressources ou, en cas de faible accès, éteindre les serveurs inutilisés et ainsi optimiser les coûts. Une haute disponibilité garantie et la possibilité de mise à l’échelle presque infinie ne sont que quelques-uns des avantages qu’apporte une solution cloud.
Dans ce qui suit, l’architecture sans serveur sera d’abord expliquée plus en détail en tant que concept global. Ensuite, les méthodes de mise à l’échelle les plus courantes utilisées par les fournisseurs de cloud seront présentées.
Qu’est-ce exactement que l’architecture sans serveur ?
Le terme « Serverless » est traduit en français par « sans serveur ». Cela ne signifie bien sûr pas qu’il n’y a plus de serveurs physiques. Cela signifie simplement que les développeurs peuvent créer et exécuter des applications sans avoir à gérer de serveurs. Les tâches de routine telles que la gestion et surtout la mise à l’échelle sont prises en charge par le fournisseur de cloud. Le code à exécuter est empaqueté par le développeur dans des conteneurs dits, qui sont ensuite exécutés par le serveur dans le cloud. Une fois les conteneurs dans le cloud, ils sont « déclenchés » via un modèle d’exécution basé sur les événements. Les « déclencheurs » fréquemment utilisés sont, par exemple, l’écriture dans une table de base de données spécifique ou la connexion d’un utilisateur. L’application peut réagir à l’événement et exécuter la fonction souhaitée de l’application dans le conteneur. Les conteneurs peuvent également agir en fonction des besoins et peuvent ainsi être automatiquement mis à l’échelle vers le haut ou vers le bas en fonction de la demande croissante ou décroissante.
La facturation est également basée sur le modèle d’exécution basé sur les événements. Cela signifie que l’on ne paie pas pour le temps pendant lequel le conteneur est disponible, mais pour le nombre et la durée des exécutions. Cela est possible car les ressources ne sont allouées dynamiquement au conteneur qu’au moment où l’événement se produit. Ainsi, aucun coût n’est encouru lorsque le conteneur n’est pas déclenché.
Les solutions sans serveur peuvent être grossièrement divisées en deux sous-catégories : Backend-as-a-Service (BaaS) et Functions-as-a-Service (FaaS). Cependant, c’est généralement cette dernière qui est désignée lorsqu’on parle de l’informatique sans serveur classique. Elles se chevauchent partiellement car dans les deux variantes, le développeur n’a que peu ou pas besoin de se préoccuper de l’hébergement du backend. Pour combiner les avantages de chaque catégorie, la plupart des grandes applications comme Instagram utilisent une forme hybride dans leurs infrastructures backend.
Functions-as-a-Service
Le modèle classique sans serveur, dénommé Functions-as-a-Service, décrit grossièrement le modèle d’exécution événementiel expliqué ci-dessus. Les développeurs rédigent une logique côté serveur qui s’exécute dans des conteneurs dès qu’un événement spécifique se produit. La logique est divisée en fonctions individuelles, chacune exécutant une action unique. La fonction peut être lancée en quelques millisecondes et traiter immédiatement les requêtes. En cas de requêtes simultanées multiples, le système copie automatiquement la fonction à plusieurs reprises. Un cas d’utilisation pour cela serait, entre autres, le traitement par lots de fichiers ou la traduction de textes entrants dans une autre langue. Le FaaS convient donc toujours lorsque l’application est sans état (ou connectée à une base de données) et/ou lorsqu’elle présente des pics de charge très irréguliers. Le FaaS offre également de nombreux avantages pour les applications asynchrones. Quelques fournisseurs populaires de fonctions cloud sont AWS Lambda, Azure Functions et Firebase Cloud Functions.
Backend-as-a-Service
Contrairement au FaaS, le BaaS n’est pas piloté par les événements. Les fonctions peuvent généralement être appelées via des API « s et sont directement mises à disposition par le fournisseur cloud. Dans ce cas, aucun code côté serveur ne doit être écrit par le développeur lui-même, mais seulement appelé via des API » s depuis l’application côté client. Les cas d’utilisation populaires sont l’authentification des utilisateurs, l’utilisation de bases de données dans le cloud ou l’utilisation de réseaux neuronaux pour les algorithmes d’apprentissage automatique.
Une grande différence réside dans la mise à l’échelle. Alors que les applications utilisées dans le modèle FaaS peuvent être facilement répliquées pour gérer les pics de charge, c’est plus compliqué avec le BaaS. Dans certains cas, le client doit effectuer manuellement la mise à l’échelle, notamment lorsque la logique de mise à l’échelle s’écarte de la réplication classique des conteneurs. Le fournisseur BaaS probablement le plus connu est Google Firebase, qui dispose de nombreuses fonctions telles que l’authentification, le stockage cloud, les bases de données en temps réel, etc. D’autres fournisseurs sont AWS et Microsoft Azure.
Comment les applications sans serveur se mettent-elles à l’échelle ?
Dès le milieu des années 1990, John Young décrit le terme de scalabilité comme suit : « La capacité [d’un système, ndlr] à maintenir le niveau de performance lorsqu’on ajoute de nouveaux processeurs ». Cela est encore utilisé aujourd’hui comme partie de la définition, mais ne décrit plus toutes les caractéristiques de la scalabilité.
Dans l’industrie informatique, un système est aujourd’hui défini comme évolutif s’il possède les capacités suivantes :
1. La capacité d’un système ou d’une application à continuer à fonctionner même lorsqu’il est modifié en taille ou en volume pour répondre aux exigences modifiées de l’utilisateur. Il est mis à l’échelle soit sur le produit lui-même (par exemple, la mémoire vive ou les cœurs de processeur), soit dans un nouveau contexte (par exemple, un nouveau système d’exploitation).
2. La capacité non seulement de fonctionner dans le nouvel environnement mis à l’échelle, mais aussi d’en tirer une valeur ajoutée. Les avantages possibles sont, par exemple, que le système peut servir simultanément plus d’utilisateurs qu’auparavant ou qu’il peut traiter les requêtes du même nombre d’utilisateurs plus rapidement.
Quel rôle joue l’élasticité ?
L’élasticité est souvent utilisée comme synonyme de scalabilité, mais en pratique, ce n’est vrai que dans une certaine mesure. Alors que la scalabilité reflète généralement les définitions données ci-dessus, c’est-à-dire la capacité d’adapter dynamiquement les ressources matérielles à la charge, l’élasticité garantit que les pics de charge sont gérés dynamiquement. C’est donc la capacité d’ajuster les ressources de manière à ce que le client paie le moins possible pour des ressources inutilisées. Cela garantit que, dans le cas idéal, les ressources disponibles correspondent exactement aux exigences actuelles. Les limites des ressources disponibles sont fixées par l’élasticité, tandis que la scalabilité se déplace dans ces limites. Idéalement, les deux se déplacent dans une sorte d’effet de synergie, car chacun d’eux n’est pas particulièrement efficace seul. L’utilisation efficace des méthodes de mise à l’échelle nécessite donc l’élasticité.
Quelles sont les méthodes de mise à l’échelle ?
La scalabilité est mise en œuvre au niveau de l’application. Les systèmes évolutifs utilisent deux méthodes pour répondre et traiter une quantité croissante de charges de travail : la mise à l’échelle verticale et horizontale.
Mise à l’échelle verticale
La première méthode de mise à l’échelle et la plus fréquemment utilisée est la dite mise à l’échelle verticale. Presque toute application, en supposant le cloud approprié, peut être mise à l’échelle verticalement de manière limitée. Cela se fait soit en transférant l’application dans une machine virtuelle plus grande, soit en allouant plus de capacité de calcul à la VM correspondante. Grâce à plus de cœurs de CPU, à un plus grand espace de stockage sur disque dur ou à une augmentation de la mémoire graphique, l’application peut ainsi servir simultanément un plus grand nombre de requêtes client.
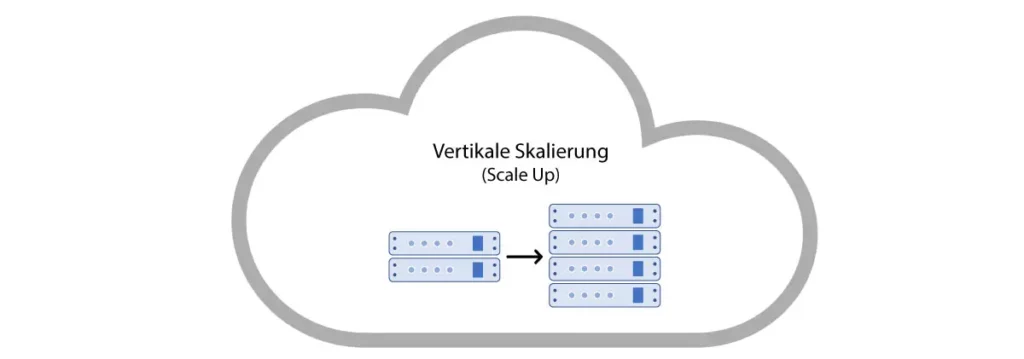
Fréquemment, la mise à l’échelle verticale n’a pas besoin d’être planifiée par le développeur d’applications, car la plupart des applications la prennent en charge nativement. Dans le cas d’une API REST, par exemple, le répartiteur de charge peut automatiquement distribuer les requêtes entrantes sur les ressources disponibles. Un inconvénient de la mise à l’échelle verticale est le temps d’arrêt du serveur, qui doit être attendu jusqu’à ce que le matériel souhaité soit ajouté ou retiré. Ainsi, les méthodes de mise à l’échelle verticale présentent toujours un risque plus élevé de pannes totales.
Mise à l’échelle horizontale
La mise à l’échelle horizontale, en revanche, décrit l’ajout de machines physiques supplémentaires au cluster. Il peut s’agir de serveurs, de bases de données, etc. supplémentaires. En augmentant le nombre de nœuds dans le cluster, la charge que chacun doit supporter est désormais réduite. Ainsi, de nouveaux points d’extrémité sont créés pour les requêtes des clients.
La mise à l’échelle horizontale est particulièrement adaptée aux systèmes basés sur les événements, car il suffit de créer plusieurs instances de la même application. Pour les Functions-as-a-Service, les fournisseurs de cloud optent généralement pour la mise à l’échelle horizontale. Pour chaque événement, un nouveau conteneur est créé qui exécute la fonction correspondante. Lorsque la capacité d’un seul nœud du cluster est épuisée, d’autres sont simplement ajoutés pour réduire la charge sur chacun. Ainsi, les applications peuvent être mises à l’échelle pratiquement à l’infini avec ce principe.
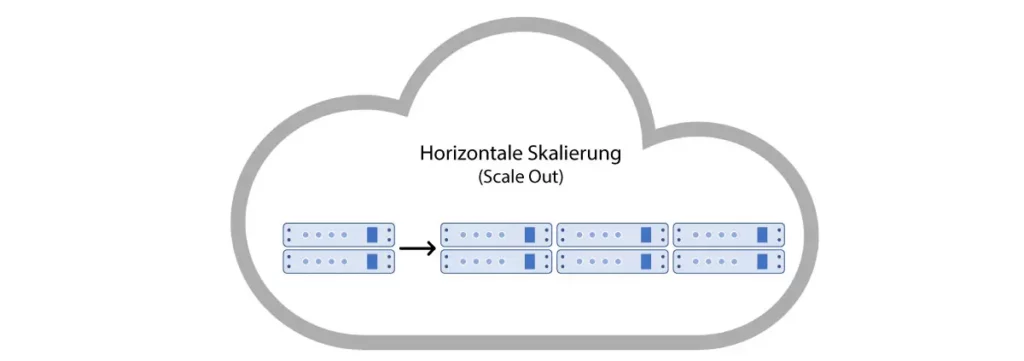
Les applications classiques telles que les API REST ont l’inconvénient de nécessiter une configuration manuelle pour pouvoir être mises à l’échelle horizontalement. Il faut ici déterminer quelle requête est transmise à quel nœud et comment la charge est généralement répartie dans le cluster de serveurs. En raison des temps d’arrêt limités du cluster et de l’adaptation rapide aux changements de charge, de nombreuses grandes entreprises Internet et services Web tels que Google, Facebook et Amazon utilisent, entre autres, la mise à l’échelle horizontale.
Conclusion
En conclusion, il convient de souligner une fois de plus que les méthodes décrites ne représentent qu’une approche théorique et qu’aucune n’est mise en œuvre exactement de cette manière dans la pratique. La plupart du temps, des formes mixtes sont utilisées pour optimiser les performances et l’efficacité des infrastructures cloud et minimiser les coûts pour le client selon le principe du paiement à l’utilisation.
La forme la plus couramment utilisée dans la réalité pourrait être qualifiée de mise à l’échelle diagonale. Elle décrit une forme mixte des deux méthodes. Dans la pratique, cela signifie que de nouvelles capacités sont mises à la disposition d’un serveur individuel jusqu’à ce que sa configuration ne le permette plus. À partir de là, le serveur est physiquement répliqué, c’est-à-dire que d’autres instances de serveur identiques sont ajoutées au cluster de serveurs.
Dans la prochaine partie de la série d’articles, une application exemple dans le cloud sera analysée en termes de sa capacité de mise à l’échelle, en examinant des facteurs tels que l’effort et les problèmes potentiels, et en accordant une attention particulière aux coûts lorsque le nombre d’utilisateurs augmente.
Sources utilisées : HOSKIN, Fletcher J. s J. J. s J. : Exploring IBM’s New-Age Mainframes – ISBN 978–1885068156 ; Skalierbarkeit ; Elastizität[/artikel_text]

