
Le choix du système d’apprentissage automatique approprié pour un problème
Avant d’utiliser l’apprentissage automatique, il convient de se demander quel type de problème il s’agit de résoudre. Comme il existe de nombreuses variantes de systèmes d’apprentissage automatique, il est judicieux de les classer en catégories plus larges selon les critères suivants :
Selon que l’on souhaite ou non qu’une personne intervienne dans le processus d’apprentissage, on choisira une approche d’apprentissage supervisé, non supervisé, semi-supervisé ou par renforcement.
Le modèle du système doit-il apprendre par étapes ou en cours de fonctionnement (en ligne vs par lots) ?
Est-il suffisant de comparer simplement de nouveaux points de données avec des points de données connus ou est-il plutôt nécessaire de reconnaître des modèles dans les données d’entraînement et de créer un modèle prédictif (apprentissage basé sur les instances vs basé sur les modèles) ?
L’une des tâches les plus courantes de l’apprentissage supervisé est la classification, telle qu’elle est utilisée dans l’exemple du filtre anti-spam. Celui-ci apprend continuellement en utilisant, par exemple, un réseau neuronal profond qui est entraîné sur des exemples. Il s’agit donc d’un système d’apprentissage supervisé en ligne basé sur un modèle. Le filtre anti-spam est entraîné avec de nombreux exemples d’e-mails et les classes correspondantes pour déterminer s’il s’agit de spam ou de ham. Le modèle du filtre anti-spam apprend ainsi à classer les nouveaux e-mails.
Une autre tâche typique des modèles d’apprentissage supervisé consiste à prédire des valeurs numériques concrètes, comme le prix d’un objet spécifique. Cette prédiction peut être effectuée dans le cadre d’une régression dite en spécifiant une série de caractéristiques, également appelées prédicteurs. Pour une prédiction des prix des voitures, les caractéristiques suivantes pourraient être prises en compte dans le modèle d’apprentissage : kilométrage, âge, marque, année du modèle. La quantité et la qualité des données d’entraînement ont généralement beaucoup plus d’influence sur la précision du modèle que le choix et l’ajustement de l’algorithme. Par conséquent, un nombre suffisant d’exemples pour les objets souhaités (par exemple, les voitures) avec leurs prédicteurs et les étiquettes correspondantes sont nécessaires pour pouvoir bien entraîner le système.
Le flux de travail de l’apprentissage supervisé
Le graphique suivant décrit le processus d’apprentissage supervisé dans la pratique.
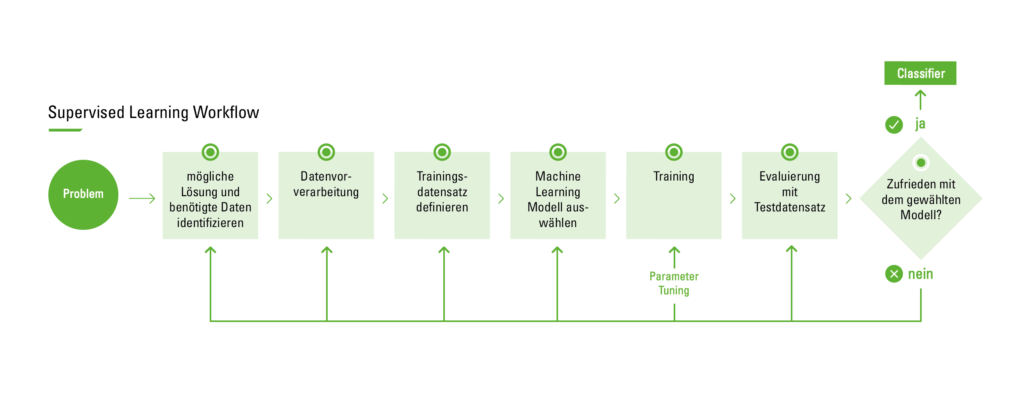
Flux de travail de l’apprentissage supervisé
Avant de commencer le processus, il est d’abord nécessaire d’identifier le problème afin de pouvoir poursuivre avec une approche de solution appropriée. Ensuite, on commence par collecter l’ensemble de données. Pour ce faire, l’avis d’un expert peut être nécessaire. Celui-ci doit évaluer quels paramètres ont le plus d’influence sur la sortie et sont donc les plus pertinents. Cependant, il ne sera pas possible de trouver un expert correspondant pour tous les cas afin d’aider à analyser les propriétés à importer. Dans ce cas, la méthode la plus simple consiste à recourir à la méthode dite de force brute. Dans ce contexte, cela signifie analyser toutes les données disponibles dans l’espoir d’isoler les propriétés correctes et pertinentes. Cependant, un ensemble de données collecté avec cette méthode doit être nettoyé et prétraité, car il contient souvent du bruit ou des valeurs de propriétés manquantes. Par bruit, on entend des valeurs aberrantes extrêmes qui ne se situent pas dans la plage des cas moyens et peuvent donc fausser les résultats de l’algorithme.
La deuxième étape consiste en la préparation et le prétraitement des données. Pour le traitement des données manquantes dans l’ensemble de données, diverses méthodes peuvent être appliquées, telles que la sélection d’instances. Celle-ci est utilisée pour gérer le bruit dans les données et pour faire face à la difficulté d’apprendre à partir de très grands ensembles de données, en aidant à éliminer les données non pertinentes. Le fait que de nombreuses caractéristiques soient interdépendantes affecte souvent la précision des modèles de classification d’apprentissage supervisé. Ce problème peut être résolu par le développement de nouvelles fonctionnalités à partir de l’ensemble de fonctions de base. Cette approche est appelée construction / transformation de caractéristiques. Les nouvelles caractéristiques générées peuvent conduire à la création de classificateurs plus précis et plus exacts. À titre d’exemple, on peut imaginer une liste de personnes où certaines n’ont pas indiqué leur poids. Pour pouvoir inclure ces personnes, on peut simplement prendre la moyenne de tous les poids et la leur attribuer. En outre, la découverte de caractéristiques significatives contribue à une meilleure compréhension du classificateur généré et à une meilleure compréhension du concept appris.
L’étape suivante consiste à sélectionner l’algorithme d’apprentissage requis. Cette étape est la plus critique. Une fois que le modèle a été testé avec les ensembles de données de test précédemment créés et que le résultat est satisfaisant, le classificateur est prêt pour l’évaluation finale avant son déploiement en routine. L’évaluation peut être basée, par exemple, sur la précision de la prédiction, c’est-à-dire le pourcentage de prédictions correctes divisé par le nombre total de prédictions. Les approches suivantes peuvent être utilisées pour calculer la précision :
Une approche consiste à diviser l’ensemble de données d’entraînement, en utilisant deux tiers pour l’entraînement. Le tiers restant est utilisé pour l’ensemble de test, où l’on essaie de déterminer la performance de l’algorithme sur des entrées inconnues.
Une autre technique bien connue est la validation croisée. Dans ce cas, l’ensemble de données d’entraînement est divisé en sous-ensembles mutuellement exclusifs de taille égale, et pour chaque sous-ensemble, le classificateur est entraîné sur l’ensemble de tous les autres sous-ensembles. La moyenne du taux d’erreur de chaque sous-ensemble est donc une estimation du taux d’erreur du classificateur.
Si, après l’évaluation du modèle, il est constaté que le taux d’erreur est insatisfaisant, il faut revenir à la phase précédente du flux de travail d’apprentissage supervisé. Il convient alors d’examiner différents facteurs : Des caractéristiques non pertinentes sont-elles utilisées pour le problème ? Un ensemble d’entraînement plus grand est-il nécessaire ? La dimensionnalité du problème est-elle trop élevée (Trop d’attributs sont-ils utilisés) ? L’algorithme choisi est-il inapproprié ? Les paramètres doivent-ils être ajustés ? Ou peut-être l’ensemble de données est-il déséquilibré ?
Comment appliquer le flux de travail décrit à un problème réel ?
Cas d’utilisation pour l’apprentissage supervisé
Pour ce cas d’utilisation, le problème est défini dans la première étape comme la prévision d’un forecast de projet. Ensuite, il s’agit de commencer à collecter l’ensemble de données. Pour ce faire, on recueille les prévisions de projets internes antérieures, qui sont déjà disponibles dans l’outil de gestion de projet propre à digatus, car les chefs de projet y documentent toutes les informations pertinentes sur les projets. En outre, il faut extraire les caractéristiques nécessaires et pertinentes pour la prévision et préparer l’ensemble de données. Pour cette étape, il est recommandé de faire appel aux chefs de projet expérimentés afin de connaître les attributs les plus importants de l’ensemble de données à transmettre au modèle d’entraînement (par exemple, le nombre d’employés, les taux horaires, les jours fériés, les modèles de congés des employés des années précédentes, etc.). Vient ensuite une étape particulièrement critique, à savoir le choix du modèle d’apprentissage automatique. Plusieurs modèles sont disponibles parmi lesquels on peut choisir. Voici quelques exemples des modèles les plus répandus en apprentissage supervisé :
1) Support Vector Machines
2) Linear regression
3) Logistic regression
4) naive Bayes
5) decision trees
6) Random Forest
7) k-nearest neighbour algorithm
8) Neural Networks (Multilayer perceptron)
Pour ce cas d’utilisation, l’approche Random Forest est choisie. Il s’agit d’un ensemble d’arbres de décision capable de résoudre à la fois des problèmes de régression et de classification avec de grands ensembles de données. Il aide également à identifier les variables les plus importantes parmi des milliers de variables d’entrée. Random Forest est hautement évolutif pour n’importe quel nombre de dimensions et offre des performances tout à fait acceptables. Enfin, il existe des algorithmes génétiques qui s’adaptent extrêmement bien à toute dimension et à toutes les données avec une connaissance minimale des données elles-mêmes, l’implémentation la plus minimale et la plus simple étant l’algorithme génétique microbien. Cependant, avec Random Forest, l’apprentissage peut être lent (selon le paramétrage) et il n’est pas possible d’améliorer itérativement les modèles générés.
Il est à présent opportun de procéder à l’entraînement du jeu de données sur le modèle sélectionné. Subséquemment à la phase d’entraînement, une phase de test sera entreprise. L’analyse des résultats des tests permettra de déterminer si le résultat est acceptable ou si une modification ultérieure des paramètres s’avère nécessaire afin d’obtenir une précision et un résultat optimaux. Il est également envisageable qu’un autre modèle d’apprentissage automatique doive être sélectionné.



