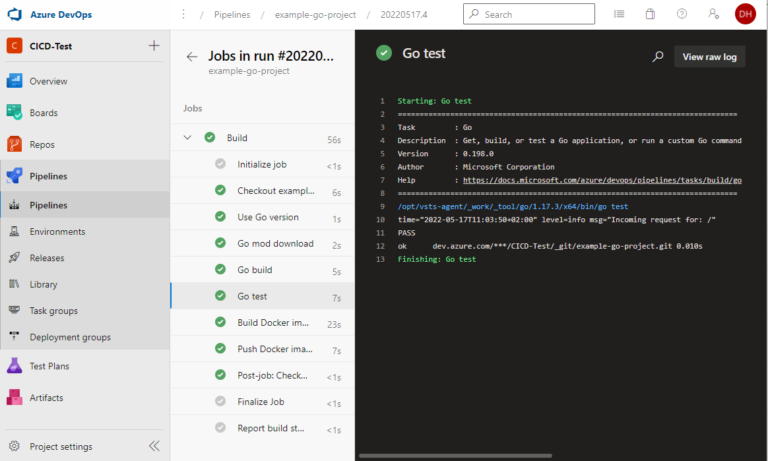
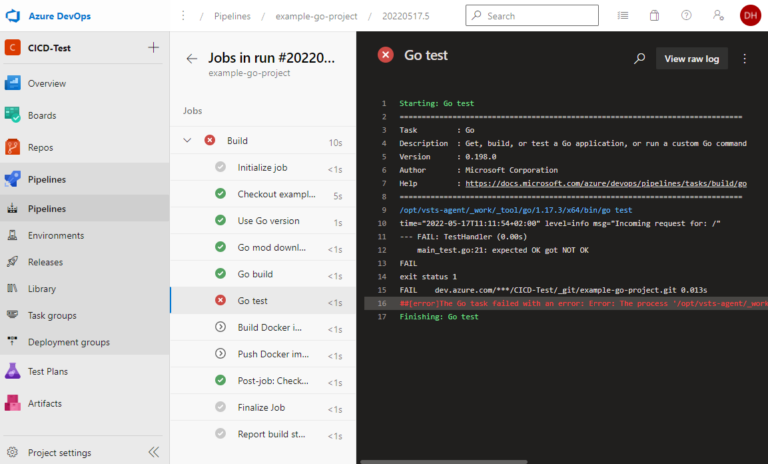
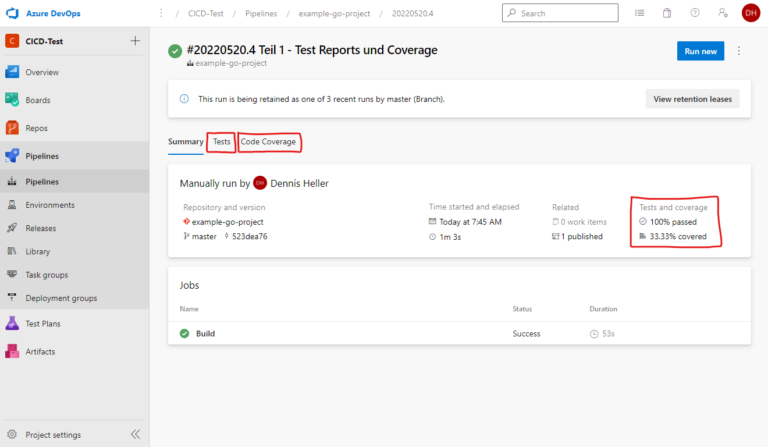
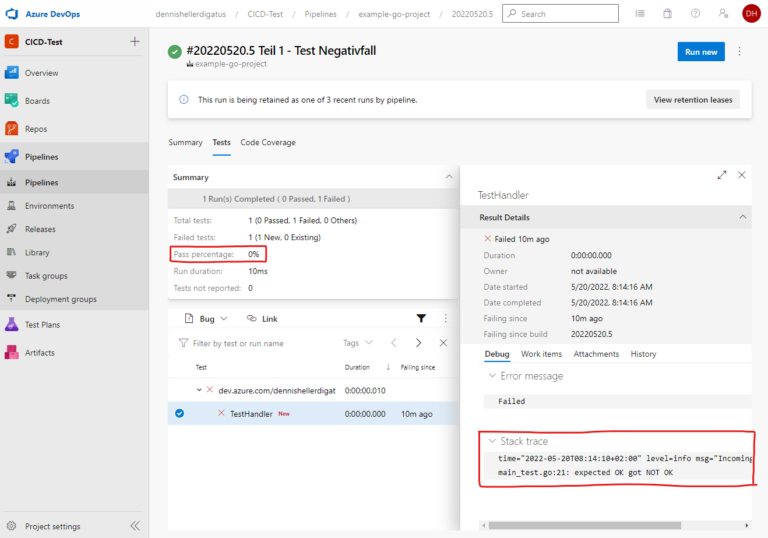
Pour vérifier précisément quel test a échoué et pourquoi, nous devons consulter le journal. Avec un seul test, ce n’est pas un problème, mais si nous avons des centaines de tests, nous n’avons pas le temps de faire défiler des milliers de lignes ici pour trouver les tests qui ont échoué. De plus, nous ne voyons pas immédiatement quel pourcentage de tests a échoué. Heureusement, Azure DevOps offre ici une interface pour fournir les résultats des tests au format XML JUnit. Pour pouvoir l’utiliser, nous devons cependant convertir la sortie de go test dans ce format.
Fort heureusement, quelqu’un d’autre a déjà fait ce travail pour nous et a écrit un outil Go correspondant : https://github.com/jstemmer/go-junit-report. Nous nous intéressons également à la couverture des tests. Ici aussi, il existe une interface d’Azure DevOps et des outils prêts à l’emploi pour la conversion au bon format.
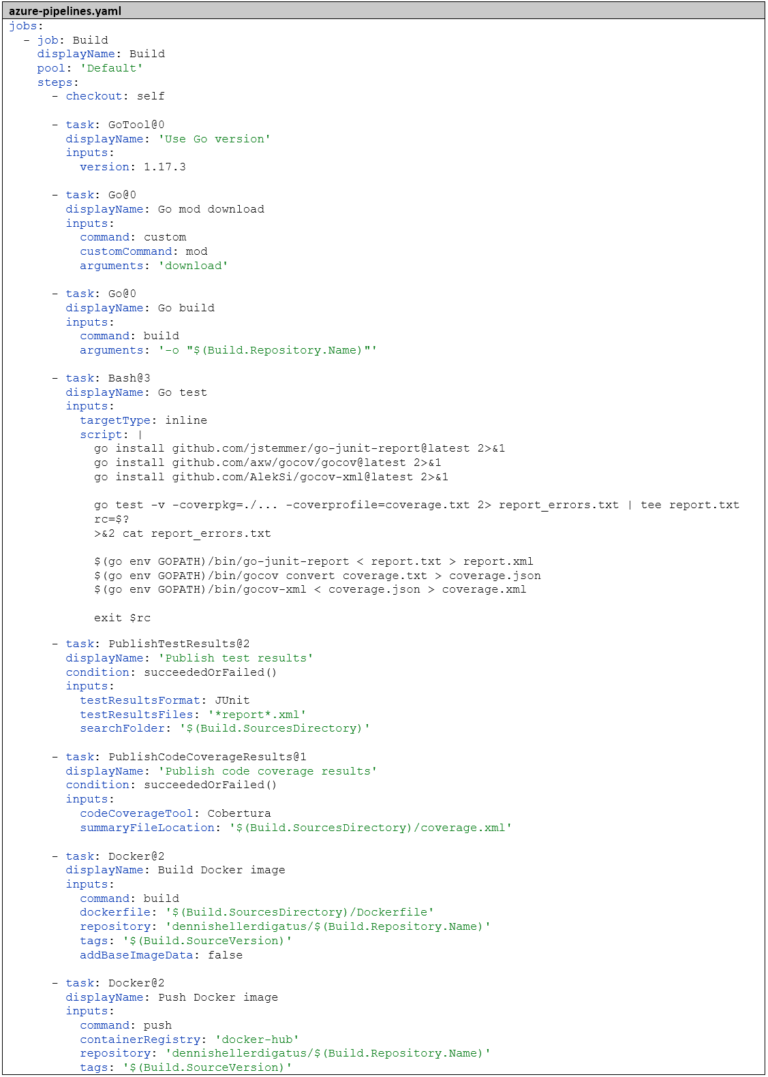
Pour ce processus complexe dans son ensemble, nous créons une tâche Bash qui accomplira les actions suivantes : Tout d’abord, elle téléchargera les outils nécessaires, puis exécutera les tests, tout en mémorisant le code de retour pour une utilisation ultérieure. En effet, nous souhaitons utiliser le code de retour de go test comme code de retour pour l’ensemble de l’étape, afin qu’Azure DevOps puisse déterminer si l’étape a échoué ou non. Cependant, avant cela, nous devons encore préparer le rapport et la couverture, tant en cas de succès que d’échec. Ensuite, nous ajouterons les deux tâches PublishTestResults et PublishCodeCoverageResults. Il est important d’ajouter ici la condition: succeededOrFailed(). Normalement, les étapes suivantes ne sont pas exécutées si une étape échoue (c’est-à-dire que la valeur par défaut est condition: succeeded()), mais avec condition: succeededOrFailed(), elles sont exécutées même si les étapes précédentes ont échoué, contrairement à condition: always(), mais pas si le pipeline a été annulé manuellement.
Note en marge, si les builds doivent s’exécuter sur un agent de build auto-hébergé : la tâche PublishCodeCoverageResults nécessite qu’un runtime .NET soit installé sur l’agent de build.
Voici maintenant le pipeline finalisé :