
Une infrastructure Functions-as-a-Service pilotée par les événements est utilisée comme application de démonstration. L’implémentation de l’application pourrait être réalisée avec tous les grands fournisseurs de cloud. Cependant, comme Amazon Web Services est actuellement le leader du marché avec environ 33 pour cent de part de marché dans le chiffre d’affaires mondial du cloud, leur calculateur de coûts a été utilisé pour le calcul des coûts. Pour des raisons d’uniformité, les services d’AWS ont également été utilisés pour toutes les fonctions employées dans l’application.
L’application de démonstration doit charger des images dans le cloud et les y stocker. Un algorithme de reconnaissance d’images doit détecter les visages dans les photos et les analyser, par exemple, pour détecter les émotions. Les informations ainsi recueillies doivent ensuite être stockées dans une base de données. En détail, l’application de démonstration doit donc remplir les tâches suivantes :
- Un client doit pouvoir charger des images dans un AWS S3 File Bucket via une interface. Toutes les images téléchargées doivent y être disponibles de manière permanente.
- Dès qu’une image est entièrement téléchargée, une fonction AWS Lambda est déclenchée.
- La fonction Lambda transmet alors l’image à l’API AWS Recognition, qui traite l’image et recherche des visages. Si des visages sont trouvés, ils sont analysés et il est possible, entre autres, de demander des données telles que l’âge possible de la personne ou les émotions que cette personne ressent actuellement.
- Dès que l’API Recognition a terminé le traitement de l’image, elle renvoie les données collectées et déclenche une autre fonction Lambda.
- La fonction Lambda enregistre alors les données collectées dans une AWS DynamoDB, où elles peuvent être interrogées. La suite du déroulement du programme n’a plus d’importance pour les besoins de cet article.

Application de téléchargement d’images (Source : AWS)
Quel est l’effort initial nécessaire pour rendre l’application évolutive ?
Comme le composant cloud est constitué de quatre services indépendants, chacun d’entre eux doit être évalué individuellement.
S3 File Bucket
Le stockage de fichiers AWS S3 offre des méthodes de mise à l’échelle automatique sans effort de configuration. Contrairement à un serveur avec des partitions, les S3 Buckets peuvent théoriquement absorber des quantités infinies d’octets grâce à la virtualisation. La distribution de copies redondantes en cas de perte de données est également prise en charge par AWS.
En catégorisant les fichiers en fonction de leurs modèles d’accès dans différentes classes de stockage, on économise en outre automatiquement de l’espace de stockage. Les fichiers souvent sollicités sont hautement disponibles. En revanche, les fichiers moins utilisés sont déplacés vers des classes de stockage moins coûteuses.
Un stockage d’objets S3 est donc capable, sans effort de configuration manuel, de s’adapter à des quantités de fichiers fortement variables et de s’étendre théoriquement à l’infini.
Fonctions Lambda
Pour chaque appel d’une fonction Lambda, AWS Lambda crée automatiquement une nouvelle instance de la fonction. Cela se produit jusqu’à ce que la limite de la région dans laquelle la fonction est exécutée soit atteinte. Pour une application en Allemagne, le centre de données de Francfort initialiserait automatiquement jusqu’à 1000 instances parallèles.
Si ce nombre ne suffit pas pour traiter les requêtes entrantes, AWS Lambda est capable de lancer jusqu’à 500 instances supplémentaires par minute. Ce processus se poursuit jusqu’à ce qu’il y ait suffisamment d’instances pour traiter les requêtes ou qu’une limite de simultanéité prédéfinie soit atteinte. Cette limite doit être définie manuellement par l’utilisateur.
Une fois un pic de charge surmonté, les instances non utilisées sont automatiquement arrêtées.
Reconnaissance d’images
L’API de reconnaissance d’images AWS est fournie par AWS et peut être directement appelée à partir des fonctions Lambda. Il n’est donc pas nécessaire de créer une instance distincte pour chaque application. La mise à l’échelle est également prise en charge par AWS et ne relève pas de la responsabilité de l’utilisateur final.
DynamoDB
AWS DynamoDB utilise le service AWS Application Auto Scaling pour adapter la capacité de débit aux modèles d’utilisation actuels. Ainsi, la capacité de débit est automatiquement augmentée lorsque la demande augmente et automatiquement réduite lorsque la demande diminue.
Le service Auto Scaling comprend une utilisation cible. Celle-ci décrit le pourcentage de débit consommé à un moment donné. La valeur peut être manuellement modifiée pour, par exemple, changer les valeurs d’utilisation cible pour les capacités de lecture ou d’écriture. Le service Auto Scaling tentera ensuite d’ajuster l’utilisation réelle de la capacité à celle spécifiée. Cependant, cela n’a de sens que si l’on peut prédire approximativement quand les pics de charge se produiront.
Dans le cas de l’application de traitement d’images, il ne faudrait pas modifier manuellement les paramètres de DynamoDB, car elle s’adapte automatiquement aux exigences changeantes dans ce contexte.
Vitesse et disponibilité
Que se passe-t-il en cas de forte augmentation de la charge et à quelle vitesse les différents services de l’application peuvent-ils réagir aux pics de charge ? Faut-il s’attendre à des pertes de performance en cas de mise à l’échelle rapide ?
Bucket de fichiers S3
Étant donné que la structure du stockage simple AWS S3 ressemble à un grand système distribué et non à un point de terminaison réseau unique, il n’y a aucune différence dans le nombre de requêtes qu’il doit traiter lorsqu’il est utilisé correctement. Comme il n’existe pas de limite au nombre de connexions simultanées, la bande passante du service peut être maximisée en augmentant le nombre de requêtes. En revanche, si aucune connexion supplémentaire n’est établie, mais qu’une seule connexion est plus fortement sollicitée, il faut s’attendre à des pertes de vitesse.
Fonctions Lambda
Le mode de mise à l’échelle des fonctions AWS Lambda a déjà été expliqué dans la section précédente. Fondamentalement, on peut donc constater que cela ne fait aucune différence pour les fonctions Lambda, tant que le nombre d’instances simultanées reste inférieur à la limite régionale (1000 en Allemagne). Cette limite peut être augmentée sur demande dans la console du centre de support AWS.
Lors du premier traitement d’une requête par une instance nouvellement créée, il faut toujours prendre en compte la durée de l’initialisation du code. Cela signifie qu’une instance nouvellement créée d’une fonction qui n’a pas encore été utilisée prendra toujours plus de temps pour traiter une tâche qu’une instance déjà utilisée. En cas de mise à l’échelle rapide, il faut donc s’attendre à un délai.
Si l’on souhaite éviter ces fluctuations de latence décrites, on peut utiliser ce que l’on appelle la simultanéité provisionnée (Provisioned Concurrency). La figure suivante illustre cela.
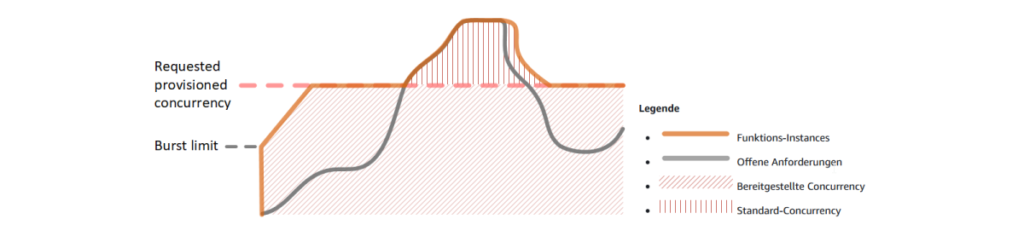
« Mise à l’échelle des fonctions avec simultanéité provisionnée (Source : AWS)
Il est évident que jusqu’à ce que la ligne rose soit atteinte (le nombre configuré de simultanéité provisionnée), le nombre d’instances de fonctions disponibles est toujours supérieur au nombre de requêtes ouvertes. Les requêtes ouvertes peuvent donc être traitées sans délai. Ce n’est que lorsque la limite est dépassée que de nouvelles instances sont lancées et qu’il faut à nouveau s’attendre à une latence accrue.
Reconnaissance d’images
Étant donné que AWS Image Recognition est un service fourni par AWS qui n’est appelé que par API, il n’y a aucune différence en termes de vitesse ou de disponibilité. Les pics de charge qui surviennent sont simplement absorbés, l’utilisateur final n’a rien à configurer.
DynamoDB
Lors de la création d’une DynamoDB AWS, le service Auto Scaling est automatiquement actif s’il n’est pas désactivé manuellement. Le fonctionnement général du service Auto Scaling a déjà été expliqué dans le chapitre précédent.
Si les valeurs du service ne sont pas modifiées, il augmente automatiquement les capacités de débit de la base de données lorsque le débit cible est trop élevé pendant une période de deux minutes. Si le débit est inférieur au débit cible souhaité pendant plus de 15 minutes, les capacités de débit sont automatiquement réduites. La figure suivante montre la capacité de débit consommée (en bleu) et fournie (en rouge) de la base de données sur une période de 24 heures.

Capacité de lecture consommée et provisionnée
Si le débit cible n’est pas trop élevé, la base de données peut répondre à toutes les requêtes de manière performante et sans perte de performance. L’espace entre la ligne bleue et la ligne rouge représente la capacité de débit libre de la base de données. Dès que la ligne bleue dépasse trop souvent la ligne rouge, il faudrait augmenter le débit cible. En règle générale, le service Auto Scaling peut cependant réagir de manière performante à tous les pics de charge et aucune perte de performance n’est à prévoir.
Comment calculer les coûts de l’application ?
La valeur initiale pour le calcul des coûts fictifs de l’application est de 1000 exécutions. Celle-ci est ensuite multipliée par un facteur de 10, la dernière valeur étant de 100 000 000 exécutions. Le fait qu’une valeur aussi élevée soit probablement plutôt rare dans la réalité est négligeable aux fins de l’évolution des coûts à ce stade. Par la suite, les coûts sont calculés individuellement pour chaque service afin de pouvoir distinguer les différentes évolutions des coûts. Enfin, un aperçu des coûts totaux de l’application est fourni. Tous les prix ont été calculés à l’aide du calculateur de coûts AWS.
S3 File Bucket
Pour le stockage S3, il faut distinguer trois éléments de coût. Premièrement, l’espace de stockage utilisé est facturé et, en outre, des coûts sont encourus pour chaque accès PUT et GET à un fichier. Lors de l’utilisation de l’application, le fichier est téléchargé exactement une fois et lu une fois à chaque exécution. Pour les valeurs suivantes, une valeur moyenne de 5 Mo par photo a été utilisée, ce qui correspond à une photo d’un appareil photo de 15 mégapixels pour une image JPEG haute résolution.
| 1000/5 Go | 100 000/5 To | 1 million/50 To | 10 millions/500 To | 100 millions/5 Po | |
| Stockage | 0,1225 | 122,5 | 1225 | 11.750 | 112.500 |
| Requête PUT | 0,0054 | 0,54 | 5,4 | 54 | 540 |
| Requête GET | 0,00043 | 0,043 | 0,43 | 4,3 | 43 |
| Total | 0,12833 $ | 123,083 $ | 1230,83 $ | 11 808 $ | 113 083 $ |
Tableau : Évolution des coûts du stockage AWS S3 en USD par rapport au nombre de fichiers et à l’espace de stockage utilisé
Le tableau montre que les accès aux fichiers jouent un rôle mineur dans les coûts, car ils évoluent de manière linéaire jusqu’à 100 millions d’appels. L’espace de stockage utilisé consomme nettement plus de coûts. Il est à noter que ses prix ne sont légèrement réduits qu’à partir de 50 téraoctets d’espace de stockage utilisé, avant cela, cette valeur évolue également de manière linéaire.
Fonctions Lambda
Les fonctions Lambda sont utilisées exactement deux fois par exécution dans l’application. Une fois lorsqu’un fichier a fini d’être téléchargé et une fois lorsque l’appel à l’API AWS Recognition est terminé. Les valeurs suivantes ont été utilisées pour le calcul des coûts.
| Mémoire vive | Durée par exécution | |
| Fonction 1 | 512 Mo | 200 ms |
| Fonction 2 | 512 Mo | 400 ms |
Tableau : Consommation de ressources des fonctions Lambda
Si l’on calcule maintenant les coûts avec les valeurs ci-dessus pour un nombre croissant d’exécutions, on obtient les résultats suivants.
| =< 1 million | 10 millions | 100 millions | |
| Fonction 1 | 0 | 11,8 | 179,8 |
| Fonction 2 | 0 | 28,47 | 346,47 |
| Total | 0 $ | 40,27 $ | 526,27 $ |
Tableau : Évolution des coûts des fonctions Lambda avec un nombre croissant d’exécutions
Si le nombre d’exécutions reste inférieur à 1 million, le service est totalement gratuit. Il est frappant de constater qu’avec l’augmentation du nombre d’exécutions, le prix n’augmente pas, mais augmente légèrement. Pour 100 millions d’exécutions de la première fonction, le prix par exécution est environ 60 % plus élevé que pour seulement 10 millions d’exécutions.
Reconnaissance d’image
L’appel à l’API de reconnaissance d’image coûte 0,001 USD par image jusqu’à un nombre de 1 million d’images. Ce n’est qu’à partir d’un nombre supérieur à un million d’images traitées que le prix baisse lentement. L’évolution ultérieure des coûts peut être consultée dans le tableau suivant.
| 1000 | 100 000 | 1 million | 10 millions | 100 millions | |
| Total | 1,2 $ | 120 $ | 1 200 $ | 8 000 $ | 60 000 $ |
Tableau : Évolution des coûts du service AWS Recognition avec un nombre croissant d’exécutions
DynamoDB
Lors du calcul des coûts pour DynamoDB, plusieurs facteurs de coût doivent être pris en compte, comme pour le stockage S3. En plus des coûts de stockage des données, des frais sont également facturés pour chaque opération d’écriture. Ceux-ci s’élèvent à 0,152 USD pour 1000 enregistrements. Pour le calcul suivant, on a supposé qu’un enregistrement contient environ 100 Ko de données. Cela donne des coûts de stockage de 3,06 USD pour 100 000 enregistrements. Les deux prix augmentent de manière linéaire et ne s’écartent pas.
Coûts totaux
En conclusion, nous examinons maintenant l’évolution des coûts totaux. Pour ce faire, les coûts totaux des services individuels ont été additionnés. Les valeurs suivantes en ont résulté :
| 1.000 | 10.000 | 100.000 | 1 million | 10 millions | 100 millions | |
| Total | 1,48 $ | 25,81 $ | 261,39 $ | 2 613,93 $ | 21 679,57 $ | 191 919,27 $ |
Tableau : Évolution des coûts totaux avec un nombre croissant d’exécutions. Pour une meilleure évaluation de l’évolution, une échelle logarithmique a été utilisée dans le diagramme suivant.

Évolution des coûts totaux avec un nombre croissant d’exécutions
L’axe des X représente le nombre d’exécutions de fonctions, l’axe des Y représente les coûts pour le nombre respectif d’exécutions. À première vue, les coûts s’échelonnent presque linéairement jusqu’au nombre final d’exécutions de 100 millions. À ce stade, les coûts s’élèvent à environ 191 919 USD. En examinant les valeurs individuelles de plus près, on constate que jusqu’à 100 000 exécutions, les coûts par exécution augmentent légèrement, puis diminuent légèrement par la suite.
Contrairement aux attentes selon lesquelles les coûts seraient considérablement réduits en pourcentage avec un nombre d’exécutions plus élevé, l’évolution est presque linéaire et il n’y a pas de grande différence dans la fréquence d’exécution de la fonction.
Difficultés potentielles et comment les éviter
Chaque application cloud peut rencontrer des problèmes et des difficultés dont il faut être conscient pour éviter les surprises. Deux des plus fréquents sont expliqués ci-dessous.
Définition de limites
Pour éviter des coûts inutiles, il est recommandé de définir des limites supérieures et inférieures. Cela peut être, par exemple, un nombre maximal d’exécutions Lambda par minute ou une limite pour le stockage S3.
Cela peut empêcher que les coûts n’augmentent de manière exponentielle en raison d’erreurs de programmation (par exemple, une récursion non désirée) ou d’attaques de serveurs. Ce problème n’existe pas sur des serveurs propres, car en cas de trafic de données excessif, le serveur planterait simplement. Dans le cloud, cependant, l’application a théoriquement la possibilité d’allouer un nombre infini de ressources. Si l’une des fonctions Lambda s’appelait elle-même dans un certain cas, AWS démarrerait un nombre illimité de nouvelles instances. Le résultat serait une facture très élevée.
Latence d’exécution/démarrage à froid
La latence de démarrage à froid décrit le délai dont un fournisseur de cloud a besoin pour démarrer le conteneur qui exécute la fonction souhaitée. Ce délai peut varier de quelques millisecondes à plusieurs secondes et peut faire paraître l’application lente. Un démarrage à froid se produit donc chaque fois qu’un nouveau conteneur doit être démarré parce qu’aucun autre n’est disponible à ce moment-là. Cela se produit principalement lorsque l’application n’a pas été utilisée pendant une période prolongée. La latence de démarrage à froid peut être réduite en diminuant le code d’initialisation de la fonction Lambda ou en « réchauffant » manuellement la fonction à intervalles réguliers.
Conclusion et perspectives
Il est évident que la mise à l’échelle de l’architecture sans serveur fonctionne très bien dans la plupart des cas sans effort de configuration manuel. Dans le cas du cloud AWS, l’application exemple peut être mise à l’échelle automatiquement. Seuls ceux qui souhaitent exploiter à 100 % les performances et les économies de coûts devraient modifier manuellement les paramètres. Cependant, il faut s’informer très précisément des effets exacts des changements. Par exemple, pour les fonctions Lambda, une simultanéité réservée peut être réservée pour des performances accrues. Cependant, cela s’accompagne d’une augmentation significative des coûts.
L’architecture sans serveur offre une bonne base pour de nombreuses applications d’entreprise. Cela est principalement dû à la haute évolutivité et disponibilité. De plus, avec le modèle de paiement à l’utilisation, c’est nettement moins cher que la location de serveurs classiques. Un autre avantage est le « time-to-market » plus rapide. Les entreprises peuvent se concentrer davantage sur leur propre produit et ont moins besoin de s’occuper de l’attente, de la configuration et de la surveillance du matériel serveur.
À l’avenir, les grands fournisseurs de cloud avec leur architecture sans serveur supplanteront très probablement complètement le centre de données classique du marché. Le seul inconvénient que de nombreuses entreprises critiquent encore dans l’informatique sans serveur est la perte de contrôle sur les données. Une fois que celles-ci se trouvent sur le serveur du fournisseur de cloud, l’utilisateur final peut difficilement y apporter des modifications. C’est surtout un problème du point de vue des entreprises européennes, car les sièges sociaux des plus grands fournisseurs de cloud sont presque exclusivement situés aux États-Unis et ne sont donc pas liés par le règlement général européen sur la protection des données. Cependant, si ce point de critique est un jour résolu, rien ne s’opposera plus à l’avenir de l’architecture sans serveur et du cloud computing.
Sources utilisées : AWS, Medium, dynamoDB auto scaling

