L'idée de cette série d'articles est née d'une situation chez un client où nous avons introduit le CI/CD car la charge de travail manuelle n'était plus gérable. Les instructions suivantes sont donc fraîchement issues de la pratique. Par souci de simplicité, nous avons abrégé le long processus d'essais et de recherche d'erreurs pour ne présenter ici que le résultat final. Les extraits de code sont exemplaires, mais suffisants pour présenter la fonctionnalité.
Partie 2 : Bibliothèques Go, modèles de pipelines et versionnement
Après avoir créé un pipeline simple dans la première partie de cette série d’articles, nous approfondissons le sujet dans la partie 2. Nous créons une bibliothèque pour notre projet Go d’exemple, qui contiendra du code commun avec d’autres futurs microservices Go. Ce faisant, nous relevons le défi de maintenir son dépôt Git privé dans Azure DevOps. Ensuite, nous créons un nouveau pipeline pour une application Python. Afin d’éviter la duplication de code dans les scripts de pipeline, nous créons un modèle de pipeline dont les deux pipelines héritent leur structure de base. De plus, nous étendons les pipelines avec un versionnement automatique utilisant des tags Git, ce qui simplifiera considérablement la gestion des dépendances et l’utilisation des images Docker publiées.
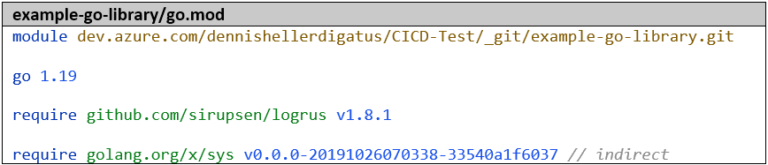
Intégration de bibliothèques Go personnelles depuis Azure Repos
La gestion des dépendances en Go est relativement simple : elle ne nécessite que l’URL d’un dépôt Git et un tag Git. Go extrait ensuite du dépôt Git le commit correspondant au tag et met le code à disposition lors de la compilation. Pour les dépôts Git publics, par exemple sur GitHub, cela ne pose généralement pas de problème. En revanche, pour les dépôts Git privés, quelques étapes supplémentaires sont nécessaires.
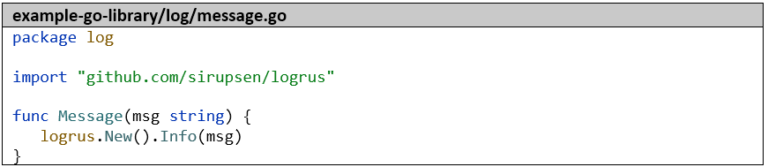
Tout d’abord, nous créons un second projet Go nommé example-go-library avec une fonction que nous utiliserons plus tard dans example-go-project.
Pour que notre bibliothèque puisse être référencée ultérieurement dans d’autres projets Go, il est impératif d’utiliser l’URL complète comme nom de module :
Sinon, nous obtiendrons des messages d’erreur de ce type :
L’importation dans example-go-project se présente alors comme suit :
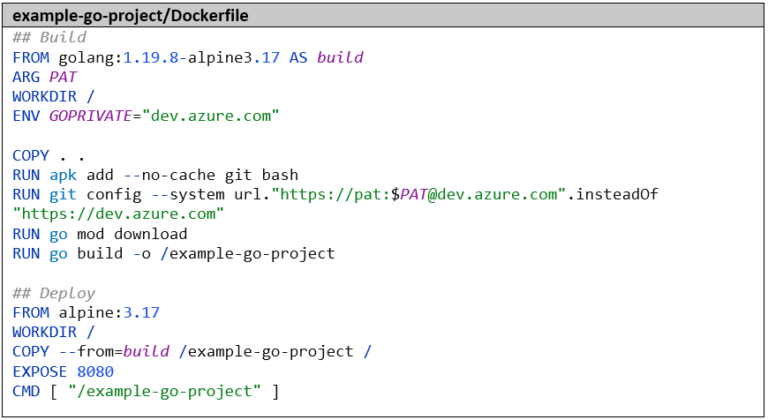
Si la bibliothèque est un dépôt Git privé comme dans ce cas, les paramètres suivants sont également nécessaires (à la fois dans l’environnement de développement local et plus tard dans le Dockerfile) :
La variable d’environnement GOPRIVATE. Elle empêche le chargement de la bibliothèque via un proxy Go public (qui n’a pas accès au dépôt Git privé).
Le paramètre Git suivant pour l’authentification (un PAT peut être créé dans Azure DevOps sous l’option de menu « Personal Access Tokens » dans le menu utilisateur en haut à droite) :
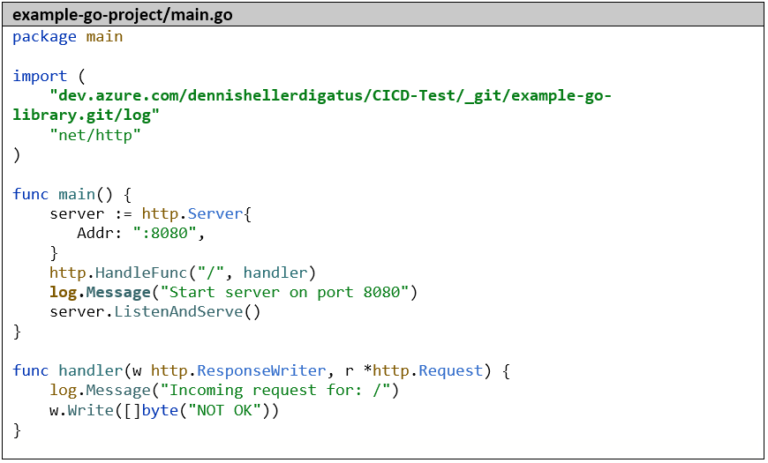
Nous prenons comme base le petit serveur HTTP de la partie 1 de cette série d’articles et remplaçons l’importation « github.com/sirupsen/logrus » par « dev.azure.com/dennishellerdigatus/CICD-Test/_git/example-go-library.git/log » et tous les appels de logrus.Info par log.Message.
Le Dockerfile doit également être adapté en conséquence pour que nous ayons accès au dépôt Git privé. Nous définissons donc ici aussi la variable d’environnement GOPRIVATE et le paramètre Git avec le PAT :
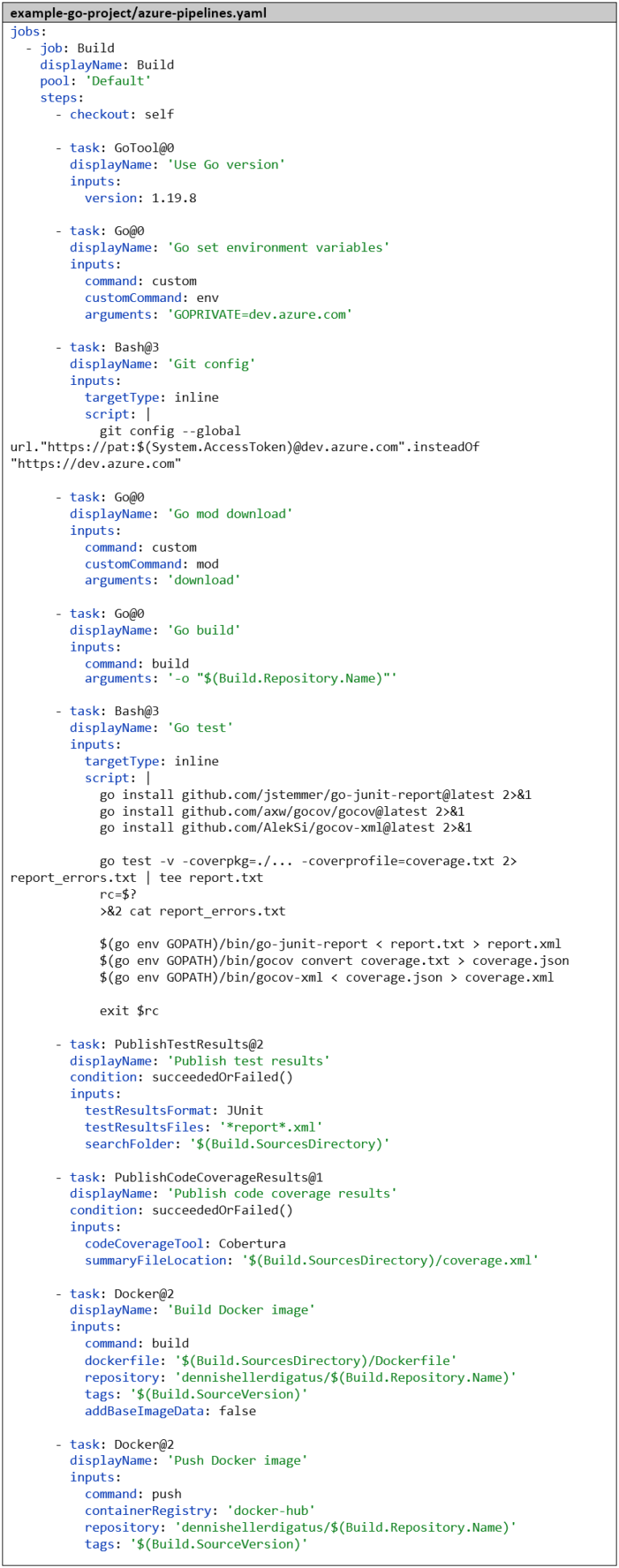
Nous devons également adapter le pipeline. Là aussi, nous effectuons les préparatifs nécessaires avant l’étape go mod download. Heureusement, nous n’avons pas besoin de publier notre PAT personnel dans le Dockerfile, mais nous obtenons un PAT généré automatiquement, car le build est déjà exécuté dans le cadre protégé de notre projet Azure DevOps. Nous l’obtenons via la variable $(System.AccessToken) et il n’est valide que pour la durée du build. Le pipeline complet se présente maintenant comme suit :
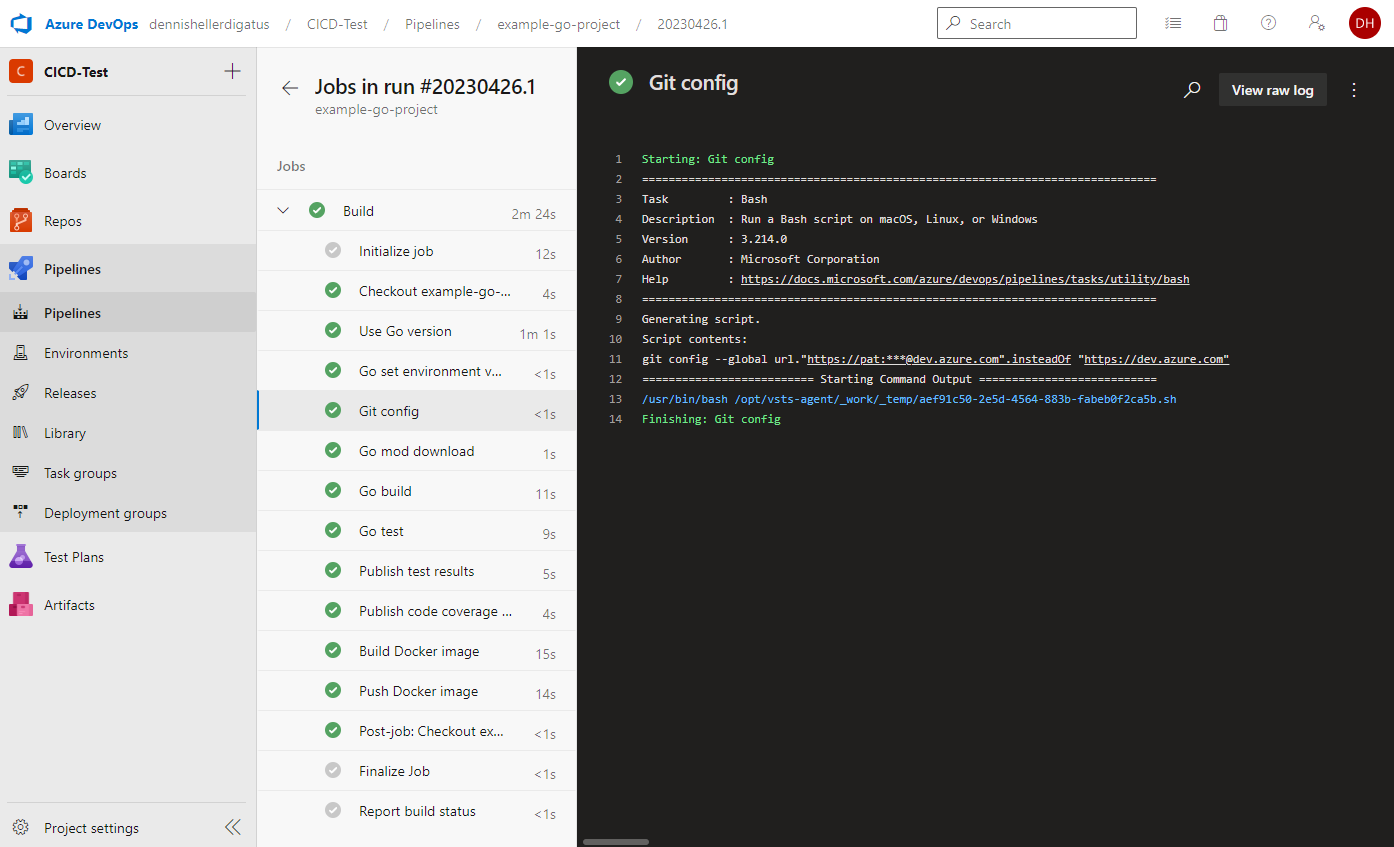
Lors de l’exécution du pipeline, nous voyons que le PAT est utilisé et masqué par Azure DevOps :
Ensuite, un test dans un shell local nous confirme que tout fonctionne toujours comme auparavant :
Même si tout semble identique de l’extérieur, nous avons maintenant l’avantage de pouvoir déplacer n’importe quel code dans la bibliothèque et le réutiliser dans d’autres projets Go. En particulier dans un paysage de microservices avec de nombreux petits services écrits en Go, il y a généralement une base de code commune, de sorte que l’introduction d’une bibliothèque peut permettre d’économiser beaucoup de code dupliqué.
Le deuxième pipeline CI – Python et Docker
Afin d’apporter un peu de diversité dans notre environnement de microservices, nous allons néanmoins changer de langage et créer un autre microservice en Python. Celui-ci devra appeler le point de terminaison REST de notre microservice Go. Naturellement, le nouveau microservice bénéficiera également d’un pipeline. Étant donné que Python, contrairement à Go, est interprété à l’exécution, l’étape de compilation est ici supprimée. Les étapes de test sont similaires à celles du pipeline Go, et les étapes Docker sont identiques. Plus tard, nous extrairons les éléments communs des deux pipelines dans un modèle de pipeline, afin d’éviter également ici la duplication de code et d’être flexibles pour d’autres pipelines futurs.
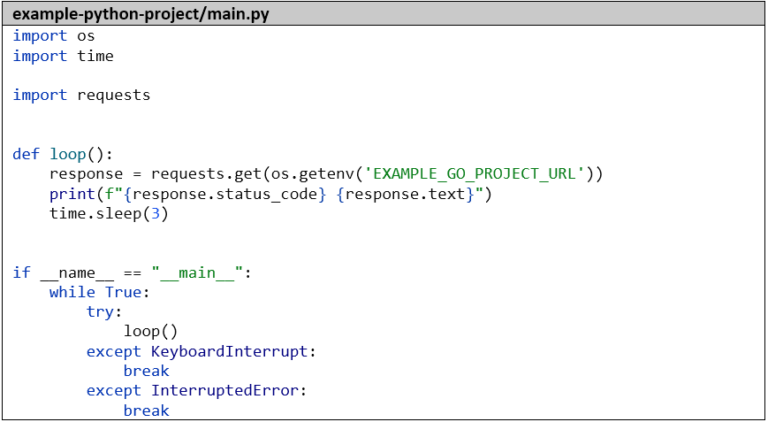
Voici le code simple de notre application Python, qui appelle simplement notre microservice Go toutes les 3 secondes et enregistre le résultat :
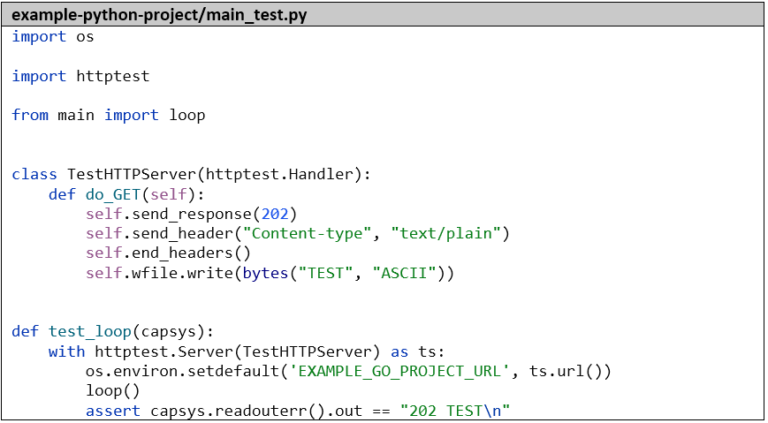
Par souci d’exhaustivité, nous créons également un petit test unitaire qui simule le microservice Go et capture la sortie standard avec capsys :
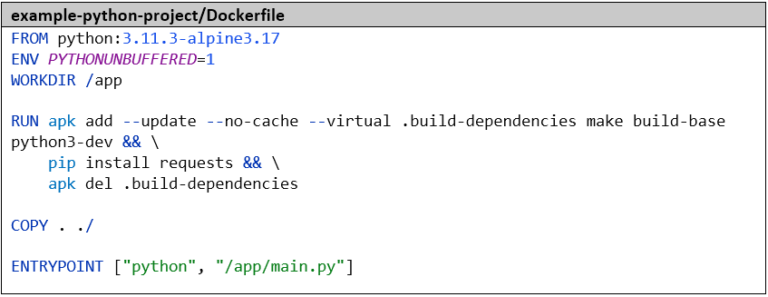
Nous empaquetons ensuite l’application dans une image Docker. La variable d’environnement PYTHONUNBUFFERED=1 est importante pour s’assurer que nous pouvons voir les sorties de journaux en temps réel. Nous installons les dépendances – dans ce cas, une seule bibliothèque, sinon nous utiliserions un fichier de requirements – avec pip.
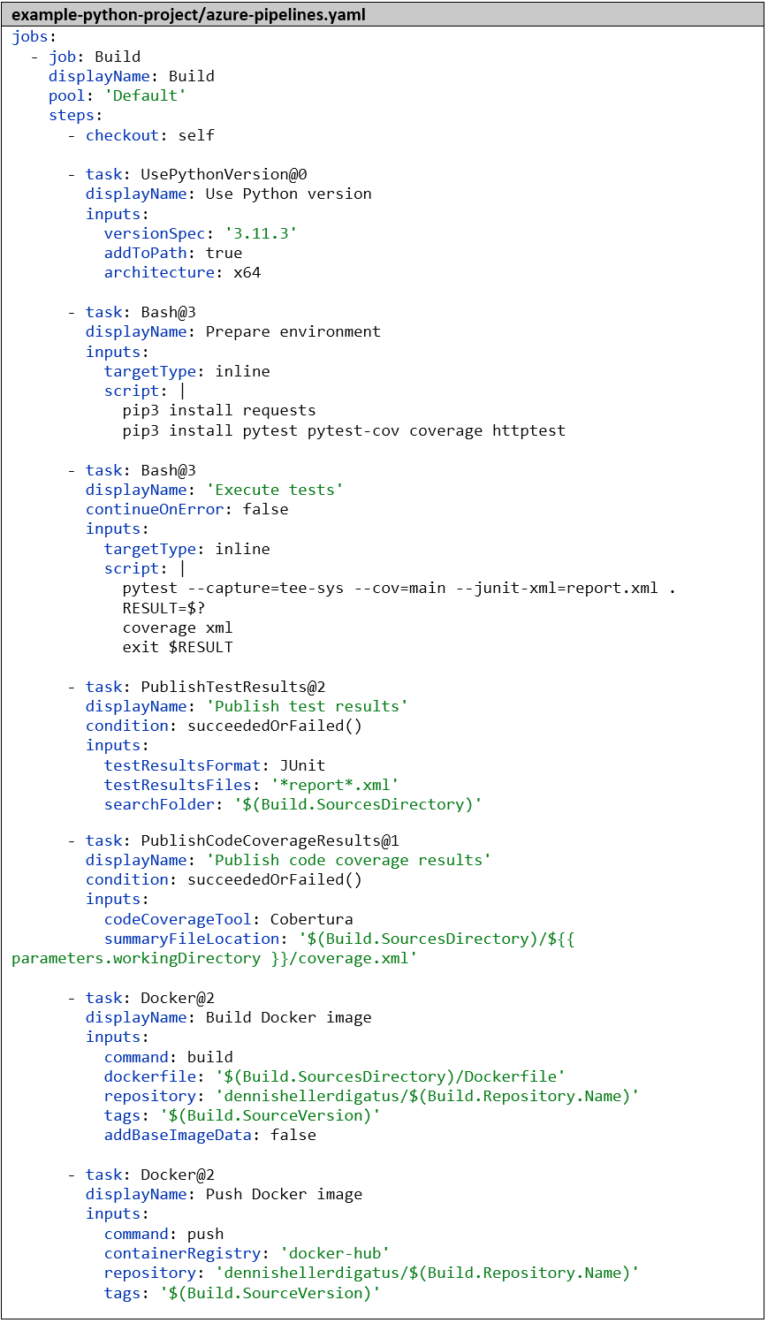
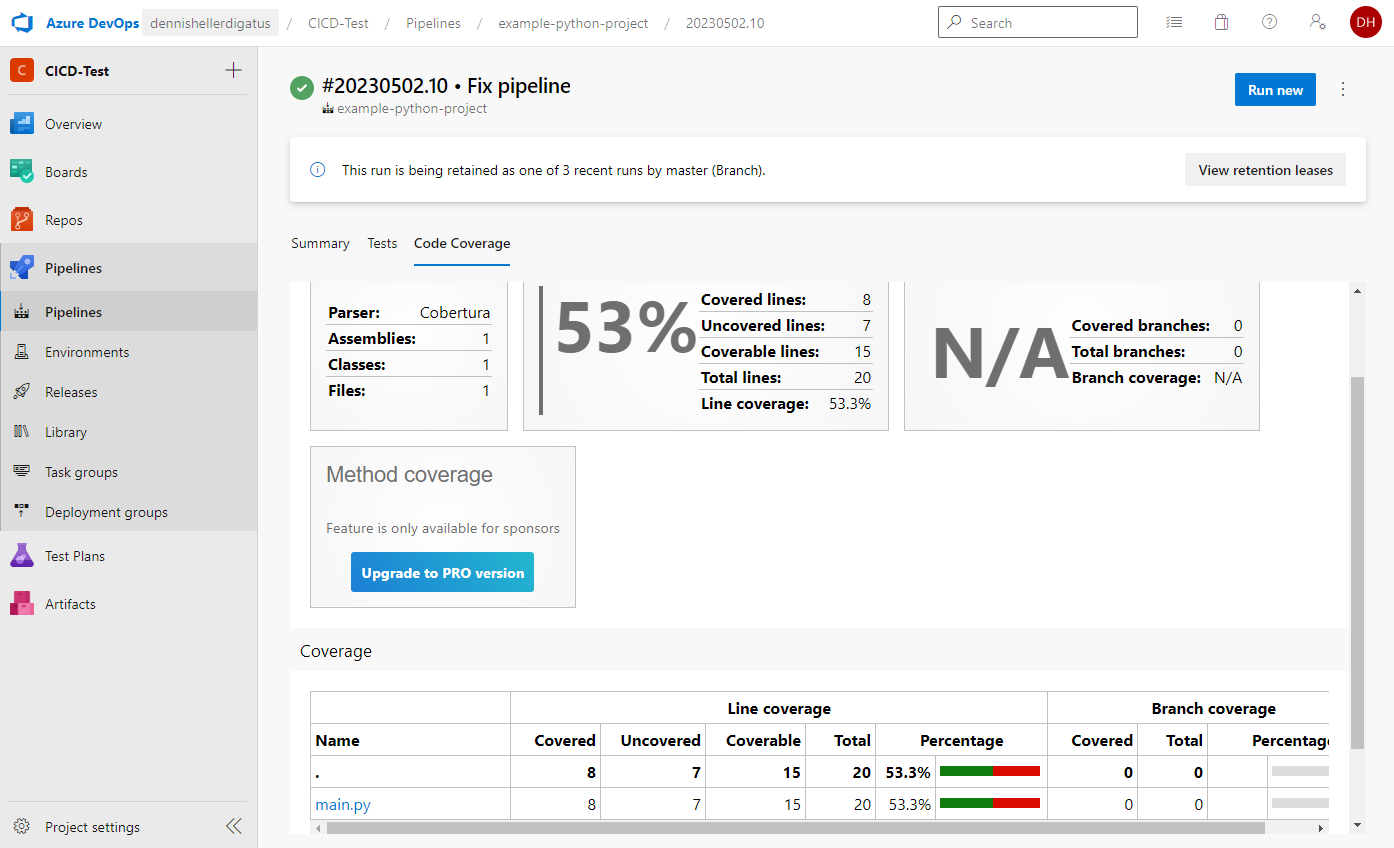
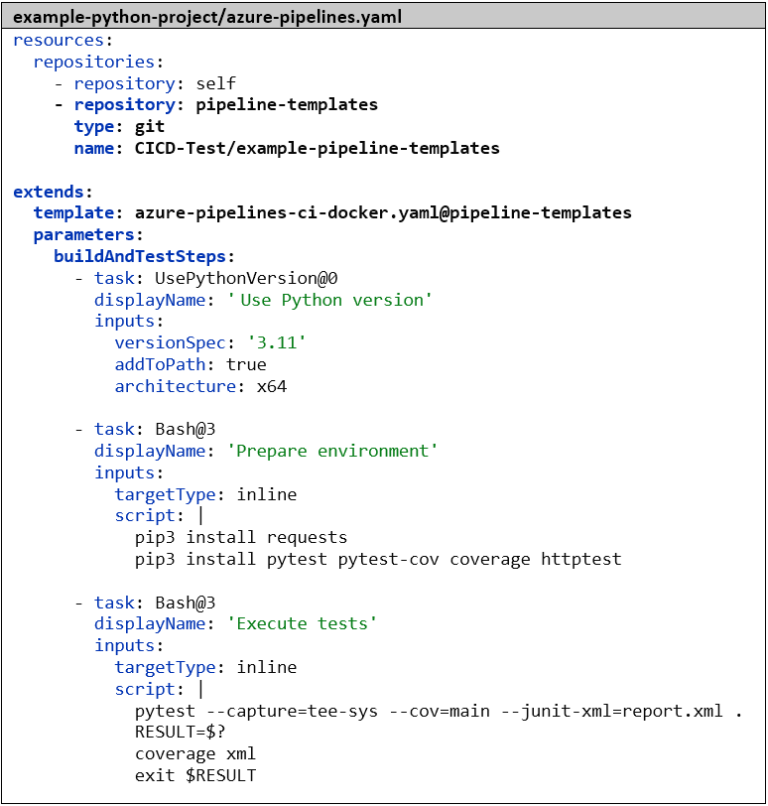
Nous créons le pipeline de manière analogue au pipeline Go. Dans la première étape, nous informons à nouveau Azure DevOps du langage et de la version avec lesquels nous souhaitons travailler – dans ce cas, Python 3.11.3. Ensuite, nous installons les dépendances, puis nous exécutons les tests avec pytest. Le paramètre –capture=tee-sys permet de capturer la sortie standard dans le test. Avec –cov=main, nous calculons la couverture de code et avec –junit-xml=report.xml, nous générons le rapport de test classique. Ici aussi, il existe déjà un outil pour préparer la couverture de code : le package Python coverage. Sans paramètres supplémentaires, il est compatible par défaut avec le format de résultat de pytest . Les étapes restantes pour publier les résultats des tests et pour construire et pousser l’image Docker sont identiques au pipeline Go :
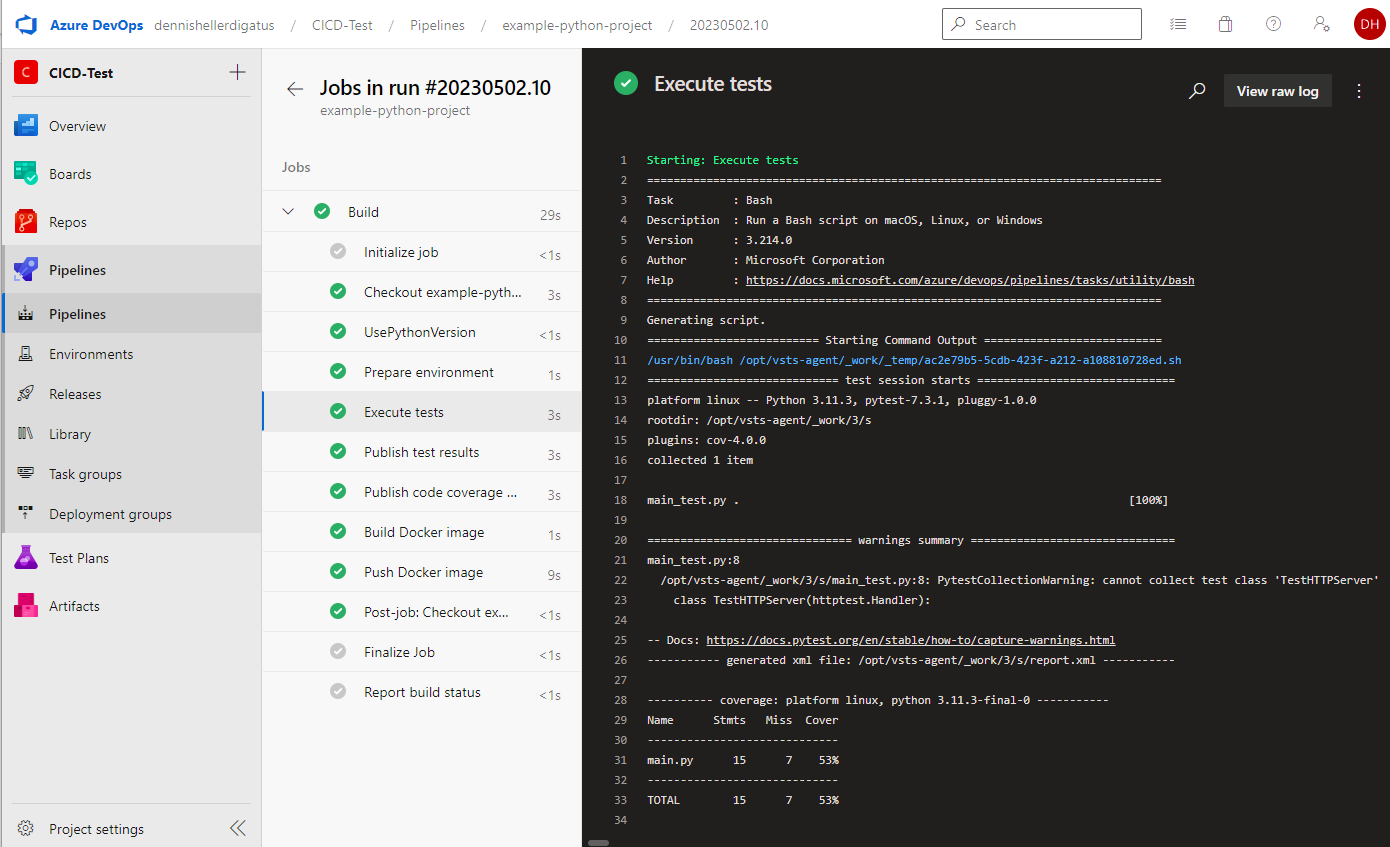
Notre premier pipeline Python est terminé. Le résultat est remarquable :
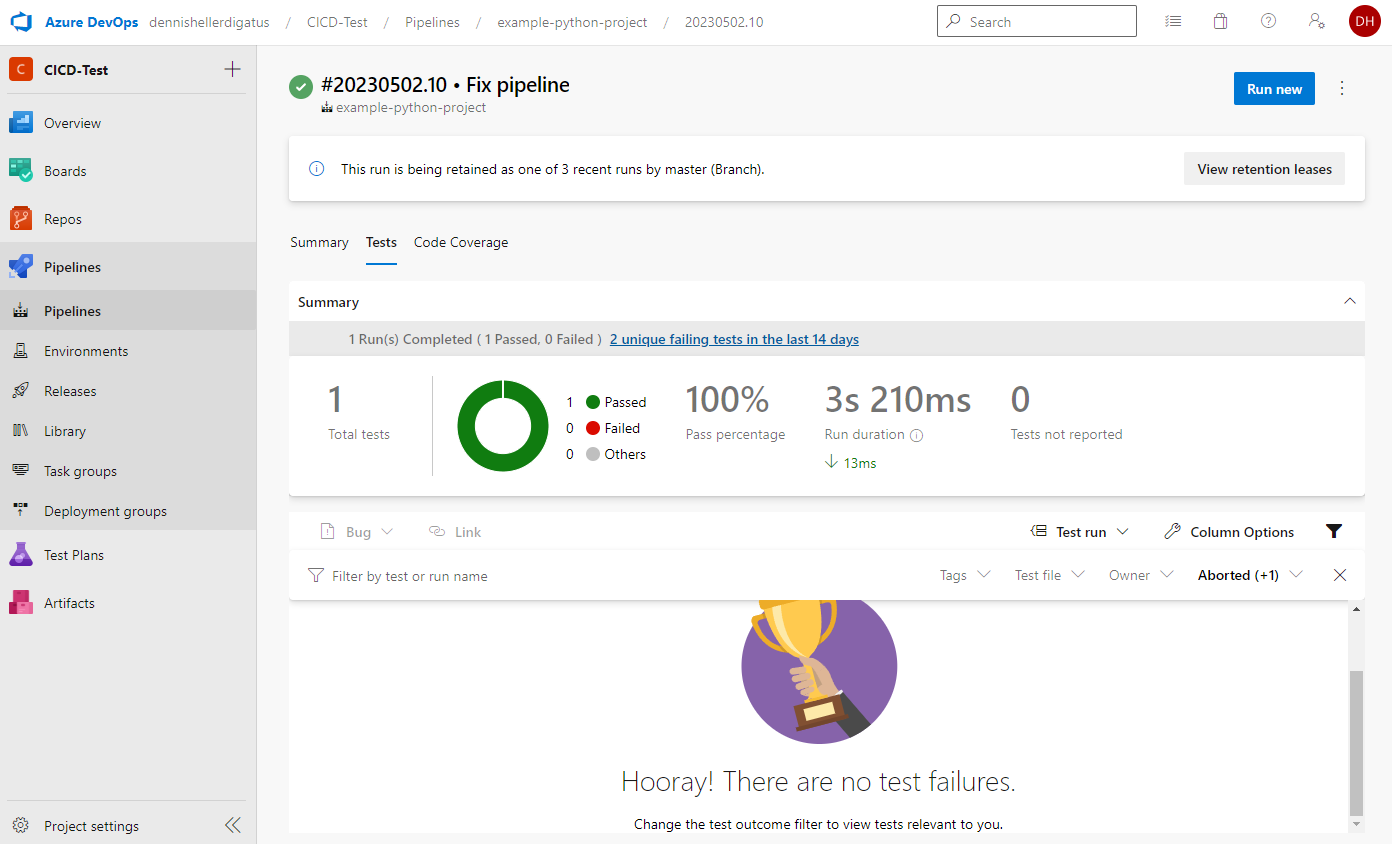
De même pour les résultats des tests et la couverture :
Penser de manière prospective : les modèles de pipeline
Si nous comparons maintenant nos deux pipelines – Go et Python – nous constatons que nous avons certaines étapes identiques et d’autres différentes. Pour économiser du travail sur les futurs pipelines, Azure DevOps nous offre la possibilité de créer des modèles de pipeline. De plus, si nous voulons modifier ou étendre ultérieurement une partie commune du pipeline, nous n’aurons alors qu’à le faire une seule fois dans le modèle commun et non dans chaque pipeline individuel.
La hiérarchie des modèles pourrait même être poussée plus loin, de sorte que nous aurions, par exemple, un modèle commun pour l’ensemble de l’entreprise, puis un sous-modèle pour le projet et d’autres sous-modèles pour CI et CD, différents langages et frameworks jusqu’au pipeline final pour un microservice. Le mot-clé pour utiliser les modèles est, comme dans la programmation orientée objet, extends:. Il est important de noter qu’un pipeline ne peut hériter que d’un seul modèle. La clé pour rendre les modèles extensibles réside dans les paramètres, qui permettent de remplir les espaces réservés dans le modèle. Ces paramètres peuvent être de simples valeurs textuelles, des nombres, des listes, des objets complexes et même des listes d’étapes complètes de pipeline. Des valeurs par défaut sont également possibles. Les paramètres d’un modèle sont déclarés tout en haut du modèle dans la section parameters: et peuvent ensuite être utilisés dans le code du modèle avec la notation suivante : {{ parameters.xxx }}. La hiérarchie des modèles et les paramètres sont évalués lors de la compilation du pipeline pour créer un seul grand script de pipeline dans lequel les paramètres sont déjà remplacés. Contrairement aux paramètres, il existe des variables dites qui peuvent être créées, modifiées et lues au moment de l’exécution. Celles-ci sont utilisées avec la notation suivante et ne sont interprétées qu’à l’exécution : $(variable). Les fichiers de modèle sont stockés comme des pipelines normaux sous forme de fichiers YAML. Comme ils sont utilisés dans plusieurs autres dépôts Git, il est judicieux de créer un dépôt Git distinct pour eux, dans notre cas, nous l’appelons example-pipeline-templates.
Revenons à nos deux pipelines : la structure de base (la publication des résultats de test et la construction et le téléchargement de l’image Docker) est identique. Seule la partie centrale, la construction et les tests, diffère. Voici un aperçu de toutes les étapes des deux pipelines :
Il est donc logique de déplacer l’étape checkout: et les 4 dernières étapes dans un modèle commun et d’utiliser un espace réservé avec un paramètre pour la partie centrale. Cela ressemble à ceci :
Si un paramètre est noté comme une entrée de liste YAML unique mais contient une liste, Azure DevOps l’étend automatiquement sans que nous ayons besoin d’écrire explicitement une boucle each. Le modèle ressemble en principe à un pipeline normal et pourrait également être utilisé comme tel. Si nous créions un pipeline dans Azure DevOps avec ce fichier modèle, nous devrions remplir manuellement les paramètres lors du démarrage du pipeline, ce qui n’est pas possible pour le type stepList. Par conséquent, la valeur par défaut serait utilisée ici : une liste vide.
Nous modifions maintenant nos deux pipelines existants pour qu’ils héritent de ce modèle et définissons les valeurs des paramètres. Pour ce faire, nous devons d’abord spécifier le dépôt Git contenant le modèle et lui attribuer un alias. Ensuite, nous pouvons spécifier le modèle avec extends : et template :. La syntaxe ici est <chemin relatif>@<alias du dépôt>. Lorsqu’un pipeline contient extends : au niveau supérieur, il ne peut pas contenir ses propres stages :, jobs : ou steps : à côté, mais l’ensemble du pipeline doit être construit sur la structure de base du modèle et toutes les modifications individuelles doivent être réalisées via des paramètres. Comme mentionné précédemment, Azure DevOps assemble un seul grand script de pipeline à partir de la hiérarchie des modèles avant l’exécution du pipeline, de sorte que nous obtenons exactement le même résultat à la fin.
Versionnement avec les balises Git
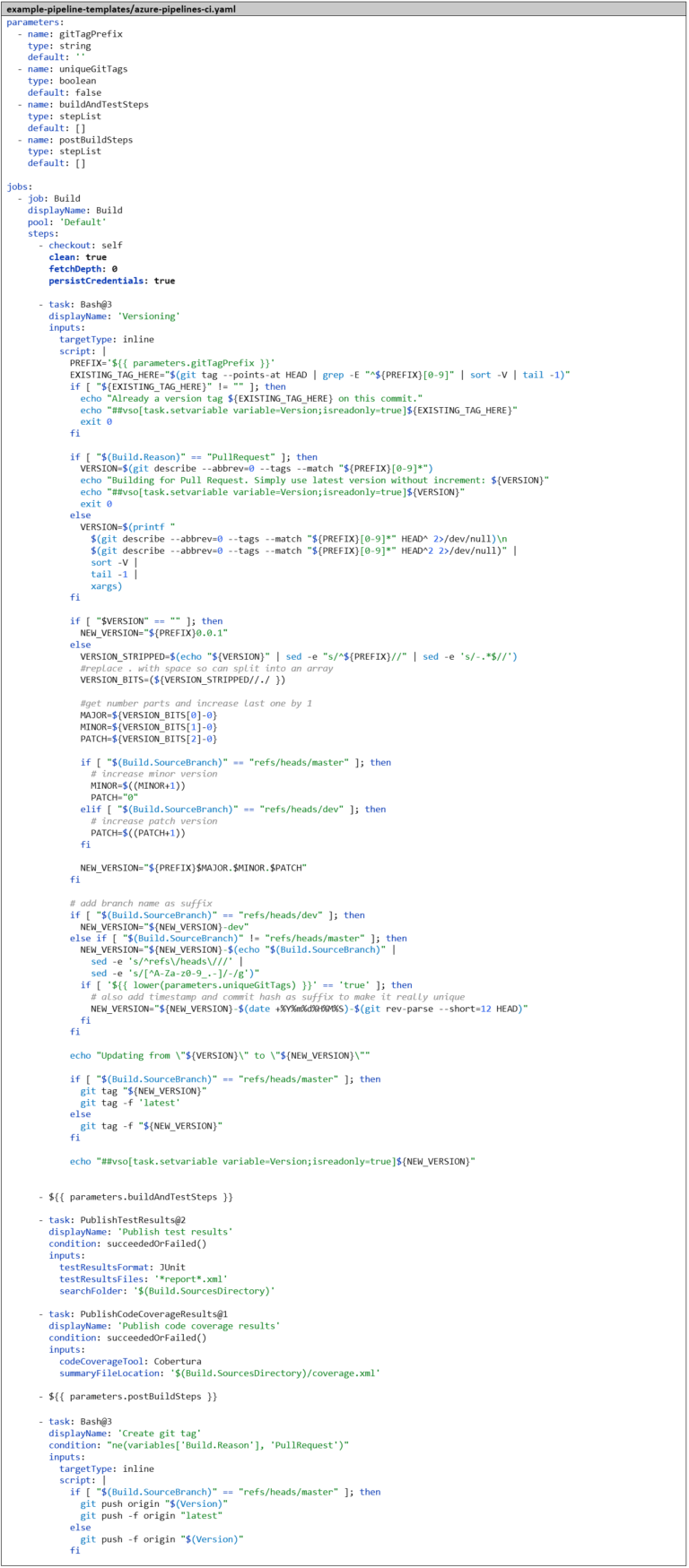
Actuellement, nous utilisons le hachage du commit Git comme balise d’image Docker, qui est difficile à mémoriser. Une balise codée en dur comme latest aurait l’inconvénient de ne pouvoir utiliser qu’une seule version en parallèle. Il est donc logique d’introduire un concept de versionnement basé sur le versionnement sémantique et de l’intégrer dans le pipeline, de sorte que le numéro de version soit automatiquement incrémenté et utilisé simultanément comme balise d’image Docker. De plus, nous créons une balise Git à chaque build pour pouvoir associer ultérieurement les images Docker au code source. Comme la logique pour cela devient relativement complexe, nous la plaçons dans un script Bash. Très probablement, nous en aurons également besoin dans les futurs pipelines CI, nous créons donc immédiatement un autre modèle azure-pipelines-ci.yaml, qui sert de nouveau modèle de base pour azure-pipelines-ci-docker.yaml. Ainsi, nous avons déjà une hiérarchie de modèles à trois niveaux.
Pour expliquer le script – nous distinguons différents cas :
Si une balise de version est déjà directement sur le commit pour lequel le pipeline s’exécute, nous la prenons et ne changeons rien à la version.
Si le pipeline a été lancé à partir d’une demande de fusion, le versionnement nous importe peu. Nous voulons simplement déterminer si le code et l’image Docker peuvent être construits et si les tests sont réussis. Nous prenons donc simplement la dernière version existante que nous pouvons trouver dans l’historique Git et ne changeons rien à la version.
Sinon, nous recherchons dans l’historique Git la balise de version la plus proche dans le passé. Si nous sommes sur un commit de fusion, nous recherchons dans les deux directions et prenons la version la plus élevée.
Si nous ne trouvons aucune version précédente, nous commençons avec la version 0.1.
Sinon, nous augmentons la version comme suit :
Sur la branche master, nous augmentons la version mineure de 1.
Sur la branche dev, nous augmentons le niveau de correctif de 1.
Sur les branches de fonctionnalités, nous n’augmentons pas le numéro de version.
De plus, nous ajoutons un suffixe au numéro de version :
Sur la branche dev-dev.
Sur les branches de fonctionnalités, une version réduite du nom de la branche.
Pour les projets Go, il est important que les balises ne soient pas déplacées, car le client Go met en cache l’ensemble du dépôt Git localement et stocke une signature pour chaque version qui ne doit plus être modifiée. Pour ce cas d’utilisation, il existe le paramètre uniqueGitTags. Lorsqu’il est défini sur true, nous créons une version unique distincte pour chaque commit en ajoutant un autre suffixe contenant le hachage du commit et un horodatage.
À partir du script Bash, nous créons une variable de pipeline d’exécution nommée Version. Cela est possible grâce à ce que l’on appelle une commande de journalisation. Pour ce faire, nous devons simplement écrire une commande spéciale dans la sortie standard du script Bash : echo« ##vso[task .setvariable variable= »<name>;isreadonly=true »]<VALEUR> ». Ainsi, la version peut être utilisée dans les étapes ultérieures du pipeline, par exemple comme balise d’image Docker. Ce n’est que si le pipeline s’est exécuté avec succès que nous repoussons la balise de version dans le référentiel Git distant, sinon elle doit être ignorée. Pour ce faire, nous forçons Azure DevOps à extraire complètement le référentiel Git à chaque exécution d’un pipeline en définissant le paramètre clean: true dans l’étape checkout:. De plus, nous devons également définir le paramètre persistCredentials: true, sinon les informations d’identification pour le référentiel Git distant seraient supprimées après l’étape checkout: pour des raisons de sécurité et nous n’aurions pas d’informations d’identification pour repousser la balise Git.
Le fichier azure-pipeline-ci-docker.yaml se réduit alors aux deux étapes Docker. Pour référencer le modèle, le nom de fichier azure-pipeline-ci.yaml suffit ici, car les deux fichiers se trouvent dans le même référentiel Git. Il est bien sûr important ici de modifier la balise de l’image Docker de « $(Build.SourceVersion) » à « $(Version) » pour utiliser le numéro de version comme balise d’image Docker. Si nous sommes sur la branche master, nous définissons – comme il est d’usage pour les images Docker – la balise latest en plus du numéro de version. De plus, nous ajoutons une condition: à l’étape « Push Docker Image »– qui fait sauter l’étape dans le contexte d’une demande de tirage. Comme pour le versionnage, dans le contexte d’une demande de tirage, nous ne sommes intéressés que par la vérification de la validité du code et non par la publication de quoi que ce soit.
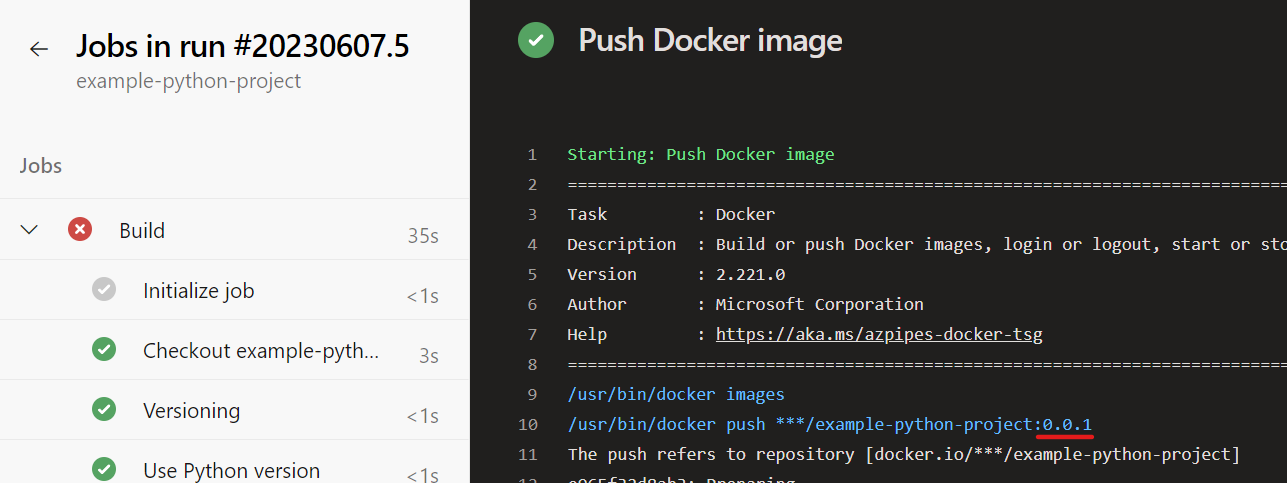
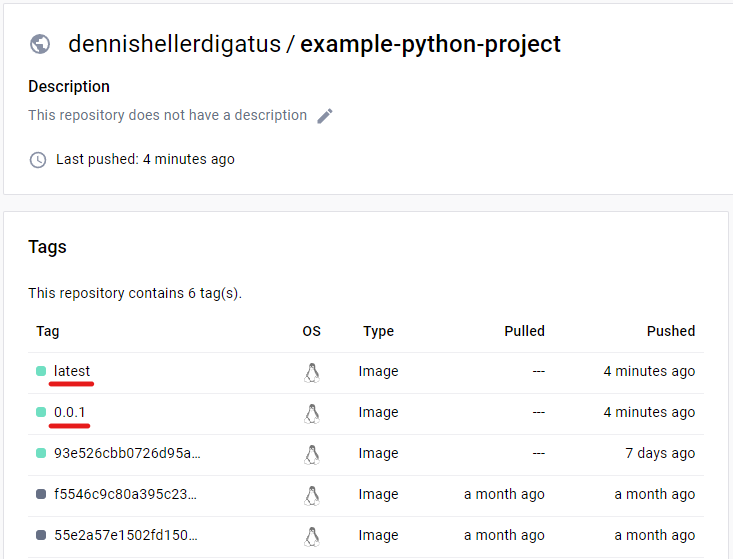
Maintenant, nous lançons le pipeline pour le example-python-project. On ne voit pas grand-chose de la grande restructuration en coulisses pour le moment. Les nouvelles étapes de construction sont Versioning et Create git tag. Comme nous n’avons pas encore d’autre balise de version, nous obtenons le message suivant : Mise à jour de « » à « 0.0.1 ».
Lors du push Docker, le numéro de version est maintenant utilisé comme balise comme souhaité :
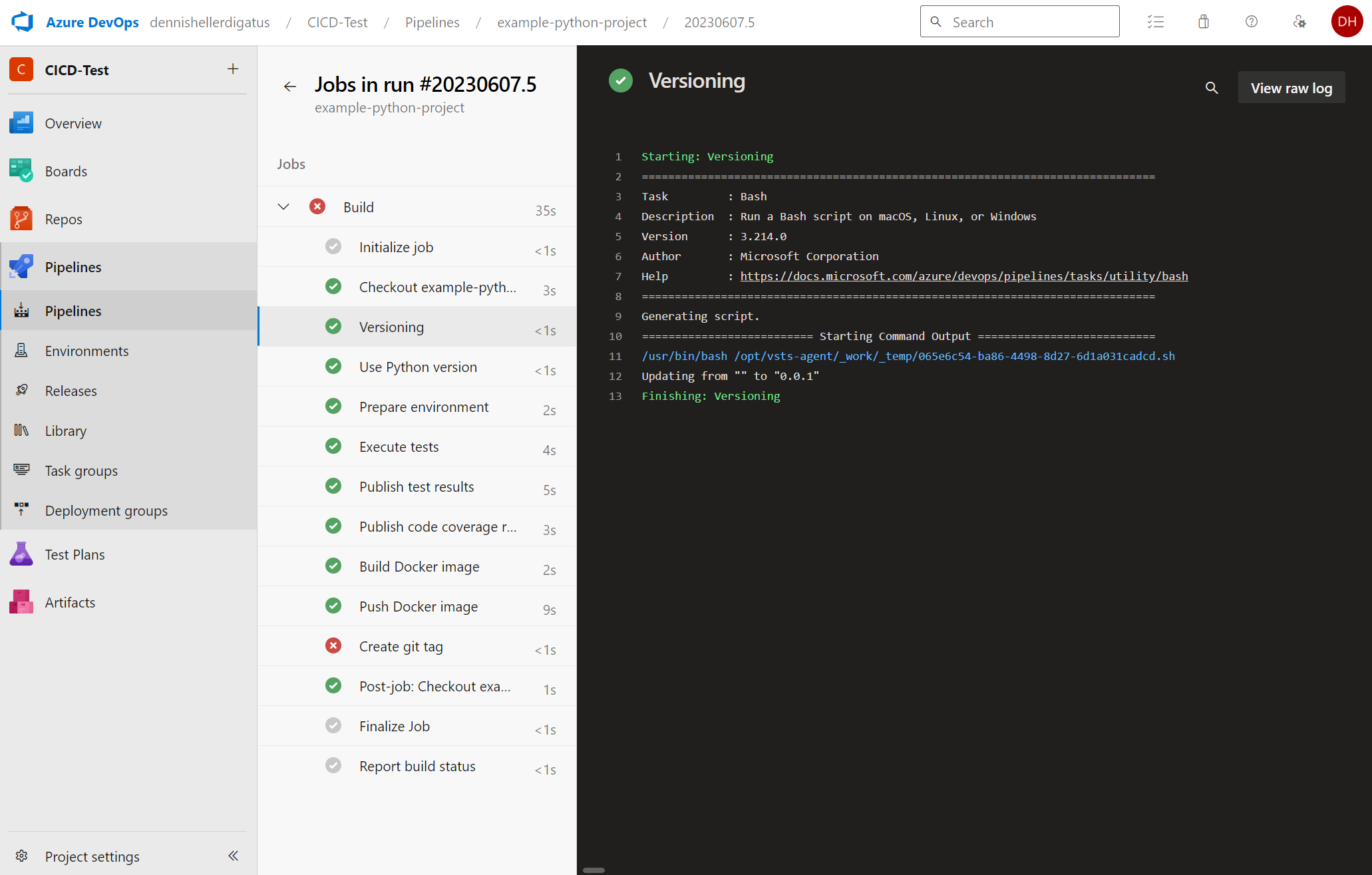
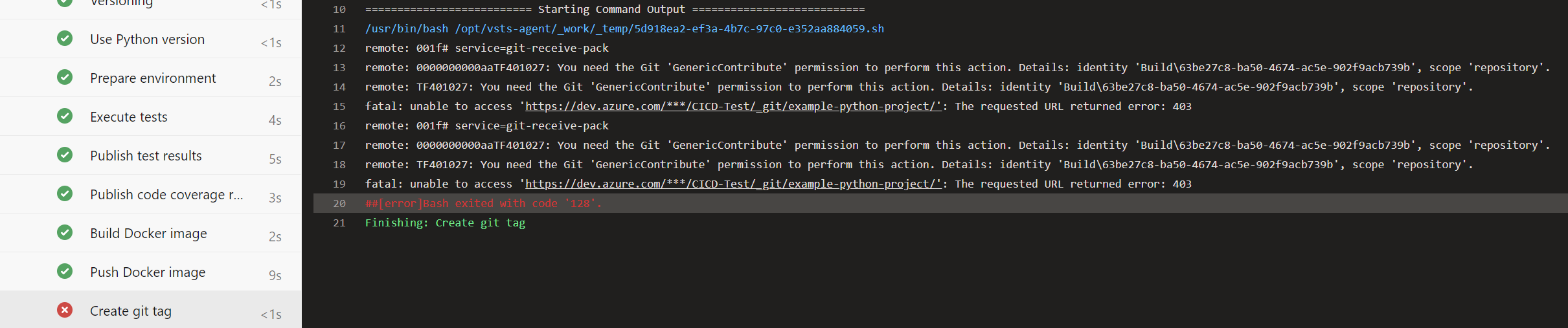
Malheureusement, le push de la balise Git échoue encore :
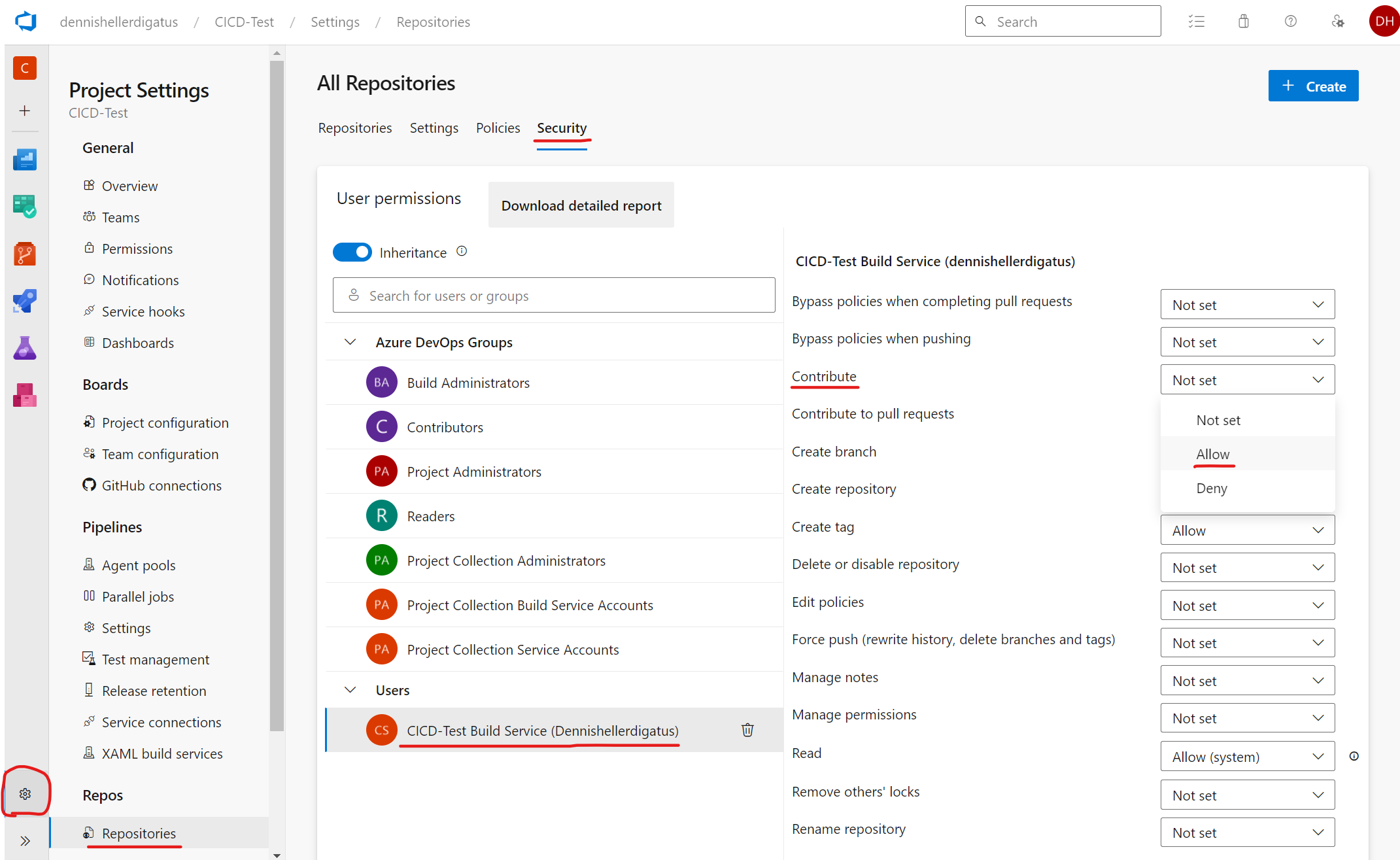
Cela est dû au fait que les pipelines dans Azure DevOps sont exécutés au nom d’un utilisateur virtuel appelé <Nom-du-Projet> Build Service (<Nom-de-l’Organisation>). Pour des raisons de sécurité, celui-ci n’a par défaut aucun droit d’écriture sur les référentiels Git. Dans notre cas, cependant, c’est souhaitable. Pour accorder l’autorisation nécessaire, nous naviguons à travers le menu via l’engrenage en bas à gauche vers « Project Settings » à « Repositories » à onglet « Security » à « Users » à « CICD-Test Build Service (dennishellerdigatus) » et modifions dans le tableau de droite la valeur pour Contribute de Not Set à Allow :
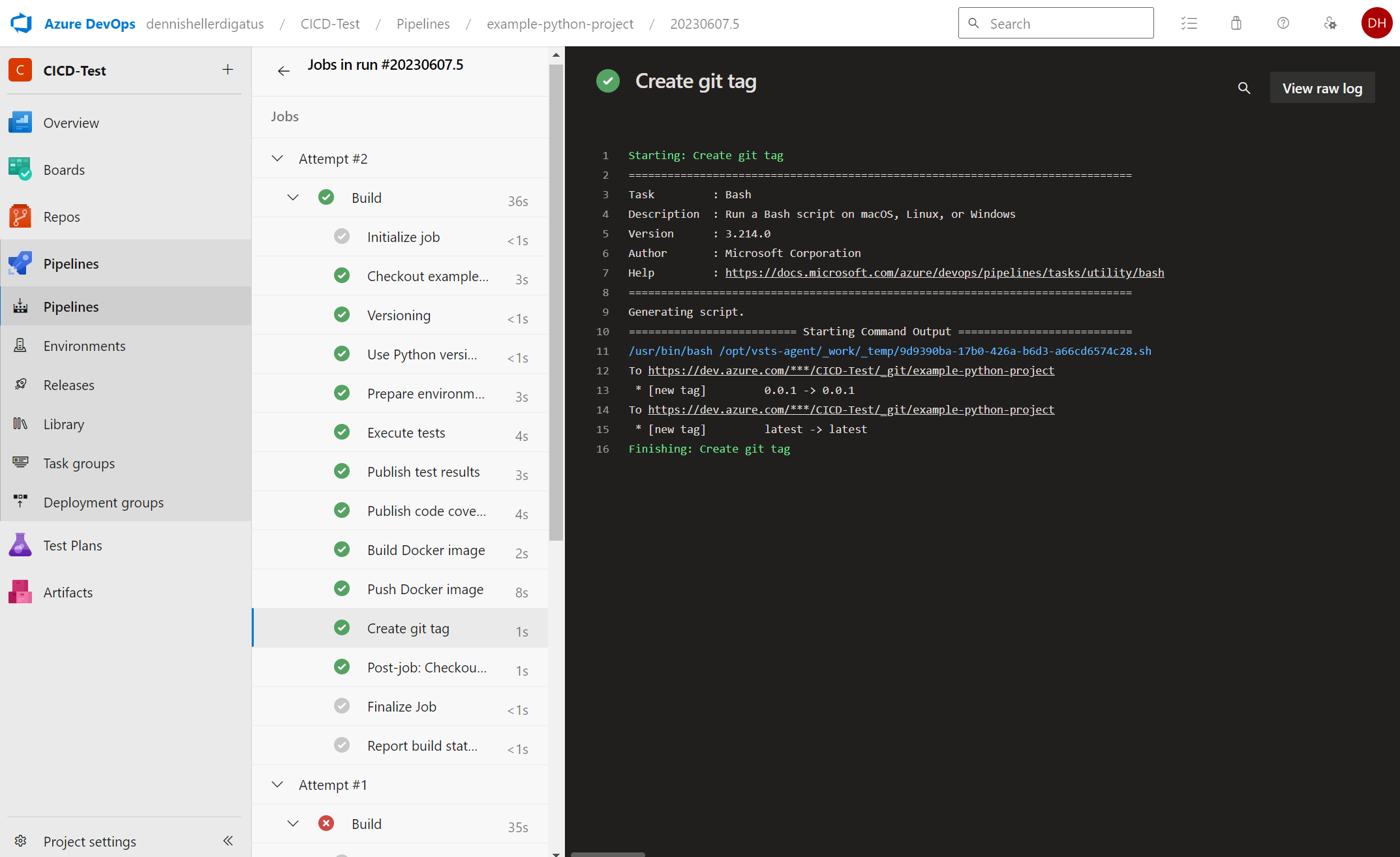
Un clic sur Rerun failed jobs dans le pipeline échoué nous montre que nous avons trouvé le bon paramètre dans la jungle des autorisations d’Azure DevOps. Le pipeline s’exécute maintenant avec succès :
Nous voyons également les nouvelles balises dans le journal Git et dans Docker Hub :
Conclusion
Azure DevOps offre une multitude de possibilités pour créer des pipelines simples et complexes. Il est agréable de constater que – contrairement à d’autres systèmes CI/CD – on peut créer rapidement et facilement des pipelines sans avoir à se préoccuper de nombreux sujets. Cela est dû au fait que les valeurs et paramètres par défaut sont très bien équilibrés entre la liberté nécessaire et la sécurité. Les fonctionnalités plus complexes sont encapsulées de manière à ne pas gêner si on n’en a pas besoin. Plus tard, on peut sortir de ces cadres petit à petit, ce qui signifie qu’on doit écrire plus de code soi-même et modifier les paramètres, mais on dispose également de plus de fonctionnalités. Ainsi, des scénarios complexes peuvent également être mis en œuvre avec des hiérarchies de modèles et des scripts Bash.
La réutilisabilité et l’extensibilité des scripts de pipeline grâce à la fonction de modèle – en particulier l’insertion de listes entières d’étapes – constituent indéniablement l’un des atouts majeurs d’Azure DevOps. Dans l’éventualité où les tâches standard s’avéreraient insuffisantes, il est toujours possible de basculer vers le niveau Bash plus complet. Là aussi, tous les outils nécessaires sont installés, tels que git, go et python. Si nous utilisons un agent de construction auto-hébergé, nous pourrions installer n’importe quels outils supplémentaires comme jq, make ou kustomize. Fort heureusement, nous n’avons guère eu à nous préoccuper des autorisations jusqu’à présent. Il existe de nombreuses options de configuration à cet égard, mais malheureusement, le fonctionnement des autorisations est parfois très difficile à appréhender. Un point positif ici est qu’Azure DevOps propose un bouton de « Quick-Fix » pour les problèmes d’autorisation fréquemment rencontrés, qui ajuste automatiquement les autorisations sur place, sans qu’il soit nécessaire de naviguer à travers des menus complexes.
Derniers articles
Fusions et acquisitions IT, Numérisation
Intégration de l’IT et de l’OT dans le cadre des processus d’acquisition
Fusions et acquisitions IT, Séparation informatique
Carve-out informatique réussi chez Trench : De la structure du groupe à un leader du marché de taille moyenne
Infrastructure informatique
Transition réussie du paysage informatique de Thüga Aktiengesellschaft et reprise du support informatique