Teil 2: CI/CD für Fortgeschrittene mit Azure DevOps
Artikel
Die Idee für diese Artikelserie entstand aus der Situation bei einem Kunden, bei dem wir CI/CD einführten, weil der manuelle Arbeitsaufwand nicht mehr zu bewerkstelligen war. Die nachfolgenden Anleitungen sind also frisch aus der Praxis entstanden. Der Einfachheit halber haben wir den langen Weg des Ausprobierens und der Fehlersuche gekürzt und präsentieren hier nur das Endergebnis. Die Code-Ausschnitte sind beispielhaft, aber ausreichend, um die Funktionalität zu präsentieren.
Teil 2: Go Bibliotheken, Pipeline Templates und Versionierung
Nachdem wir in Teil 1 dieser Artikelserie bereits eine einfach Pipeline erstellt haben, tauchen wir in Teil 2 etwas tiefer in die Materie ein. Wir erstellen für unser Go-Beispiel-Projekt eine Bibliothek, die gemeinsamen Code mit anderen zukünftigen Go-Microservices enthalten wird. Dabei haben wir die Herausforderung, dass dessen Git-Repository in Azure DevOps privat bleiben soll. Danach erstellen wir eine neue Pipeline für eine Python-Anwendung. Um doppelten Code in den Pipeline-Skripten zu vermeiden, erstellen wir ein Pipeline-Template, von dem beide Pipelines ihre Grundstruktur erben. Außerdem erweitern wir die Pipelines um eine automatische Versionierung mit Git Tags, was die Abhängigkeitsverwaltung und die Verwendung der publizierten Docker-Images deutlich vereinfachen wird.
Einbinden eigener Go-Bibliotheken aus Azure Repos
Die Abhängigkeitsverwaltung in Go ist relativ simpel: es benötigt nur die URL zu einem Git-Repository und einen Git Tag. Go checkt dann aus dem Git-Repository den Commit mit dem entsprechenden Tag aus und stellt den Code beim Kompilieren zur Verfügung. Für öffentliche Git-Repositories, zum Beispiel auf GitHub, kann nicht viel schiefgehen. Für private Git-Repositories dagegen braucht es ein paar extra Handgriffe.
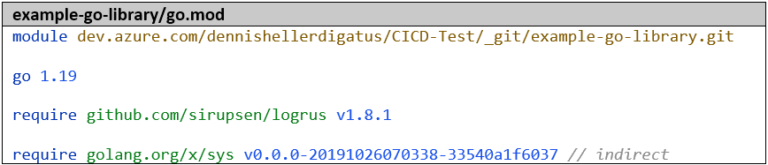
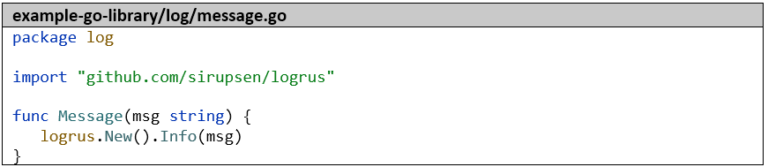
Zuerst erstellen wir ein zweites Go-Projekt namens example-go-library mit einer Funktion, die wir später im example-go-project verwenden wollen.
Damit unsere Bibliothek später in anderen Go Projekten referenziert werden kann, ist es zwingend notwendig, die volle URL als Modul-Namen zu verwenden:
Ansonsten bekommen wir Fehlermeldungen folgender Art:
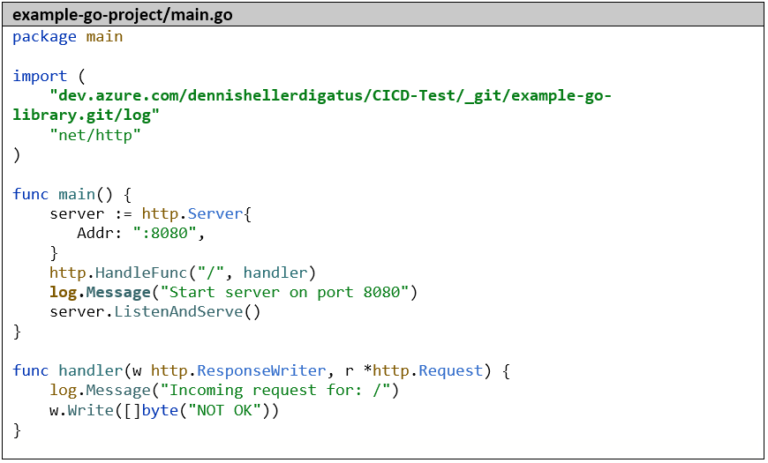
Der Import im example-go-project sieht dann wie folgt aus:
Falls die Bibliothek wie in diesem Fall ein privates Git-Repo ist, sind außerdem folgende Einstellungen nötig (sowohl in der lokalen Entwicklungsumgebung als auch später im Dockerfile):
Die Umgebungsvariable GOPRIVATE. Sie verhindert, dass die Library über einen öffentlichen Go-Proxy geladen wird (der ja keinen Zugriff auf das private Git-Repository hat).
Das folgende Git-Setting für die Authentifizierung (ein PAT kann in Azure DevOps unter dem Menü-Punkt „Personal Access Tokens“ im Benutzer-Menü oben rechts erstellt werden):
Wir nehmen als Grundlage den kleinen HTTP-Server aus Teil 1 dieser Artikel-Serie und ersetzen den Import „github.com/sirupsen/logrus“ durch „dev.azure.com/dennishellerdigatus/CICD-Test/_git/example-go-library.git/log“ und alle Aufrufe von logrus.Info durch log.Message.
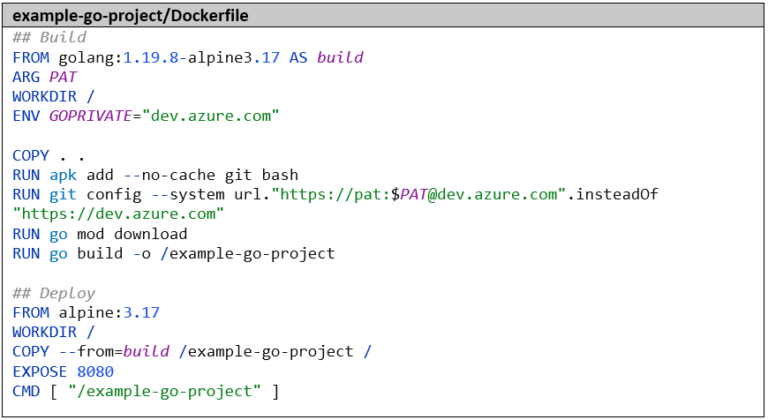
Das Dockerfile muss auch entsprechend angepasst werden, damit wir dort Zugriff auf das private Git-Repository haben. Wir setzen also auch hier die Umgebungsvariable GOPRIVATE und das Git-Setting mit dem PAT:
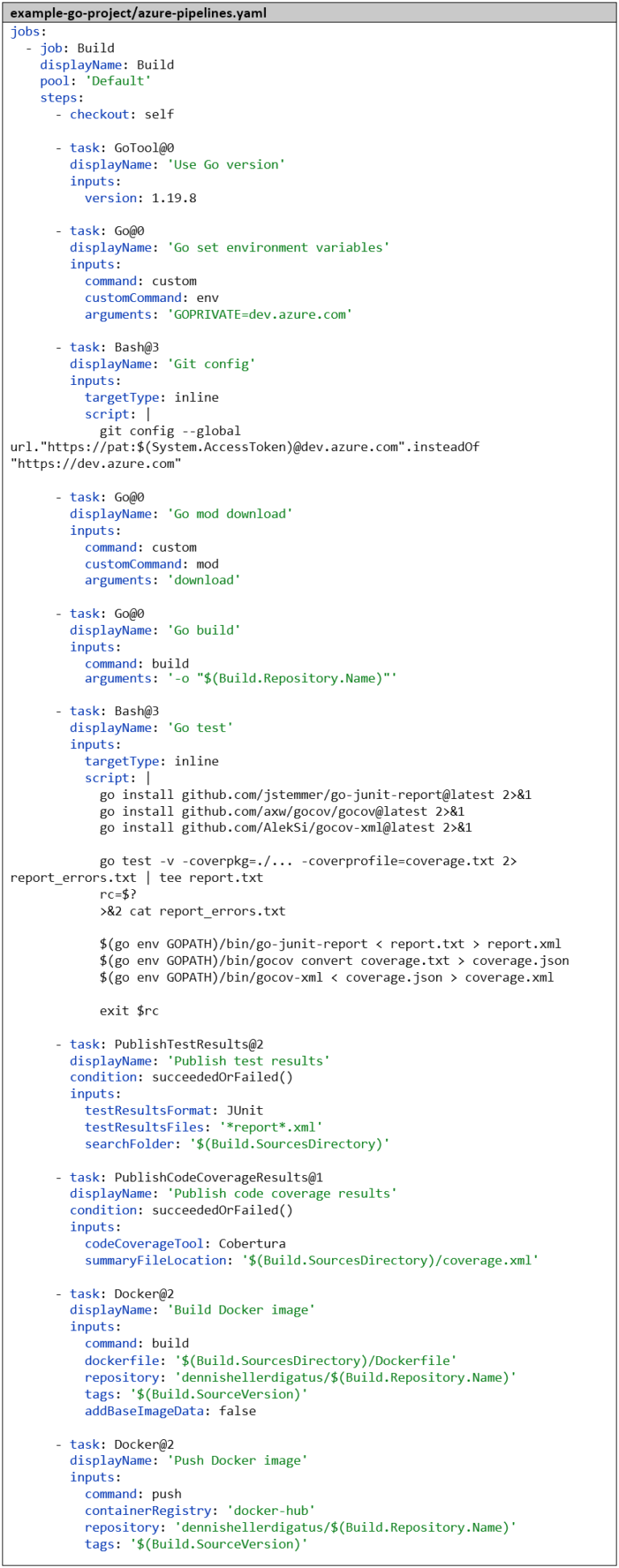
Die Pipeline müssen wir ebenfalls anpassen. Auch dort treffen wir vor dem go mod download-Step die nötigen Vorbereitungen. Erfreulicherweise müssen wir hier nicht unseren persönlichen PAT im Dockerfile veröffentlichen, sondern bekommen einen automatisch generierten PAT, da der Build ja bereits im geschützten Rahmen unseres Azure-DevOps-Projekts ausgeführt wird. Diesen bekommen wir über die Variable $(System.AccessToken) und er ist nur für die Dauer des Builds gültig. Die komplette Pipeline sieht nun wie folgt aus:
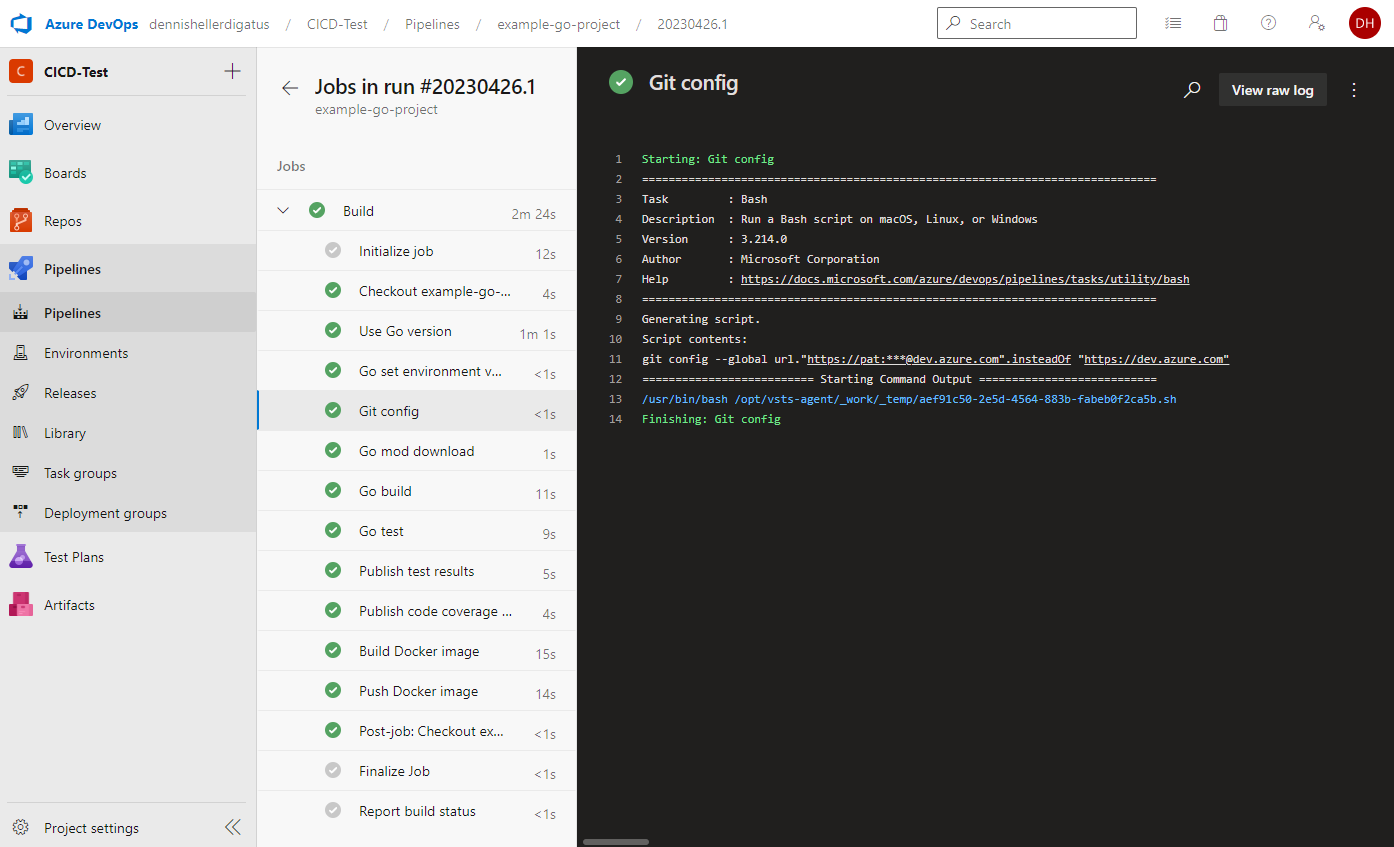
Beim Ausführen der Pipeline sehen wir, dass der PAT eingesetzt und von Azure DevOps maskiert wird:
Danach bestätigt uns ein Test in einer lokalen Shell, dass immer noch alles wie bisher funktioniert:
Auch wenn nach außen alles gleich aussieht, haben wir jetzt den Vorteil, dass wir beliebigen Code in die Bibliothek verschieben und in anderen Go-Projekten wiederverwenden können. Gerade in einer Microservice-Landschaft mit vielen kleinen, in Go geschriebenen Services, gibt es meistens eine gemeinsame Code-Basis, sodass man durch die Einführung einer Bibliothek viel Duplicate Code sparen kann.
Die zweite CI Pipeline – Python und Docker
Um etwas Abwechslung in unsere Microservice-Landschaft zu bringen, wechseln wir nun dennoch die Sprache und erstellen einen weiteren Microservice in Python. Dieser soll den REST-Endpunkt unseres Go-Microservices aufrufen. Natürlich bekommt der neue Microservice auch eine Pipeline spendiert. Da Python in Gegensatz zu Go erst zur Laufzeit interpretiert wird, fällt hier der Build-Step weg. Die Test-Steps sehen ähnlich aus wie in der Go-Pipeline und die Docker-Steps sind identisch. Später werden wir die Gemeinsamkeiten beider Pipelines in ein Pipeline-Template extrahieren, um auch hier Duplicate Code zu vermeiden und für zukünftige weitere Pipelines flexibel zu sein.
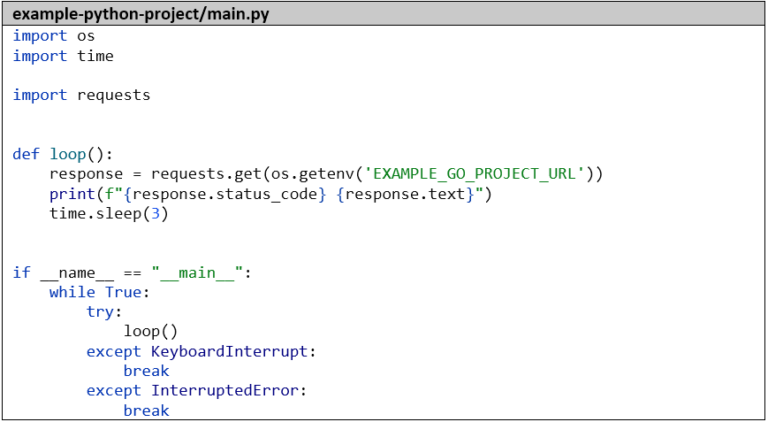
Hier der simple Code unserer Python-Anwendung, die einfach im 3-Sekunden-Takt unseren Go-Microservice aufruft und das Ergebnis loggt:
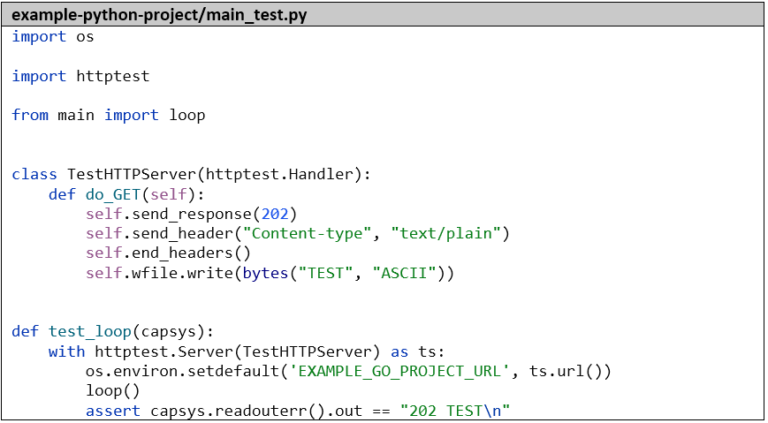
Der Vollständigkeit halber erstellen wir noch einen kleinen Unit-Test, der den Go-Microservice mockt und mit capsys die Standardausgabe abfängt:
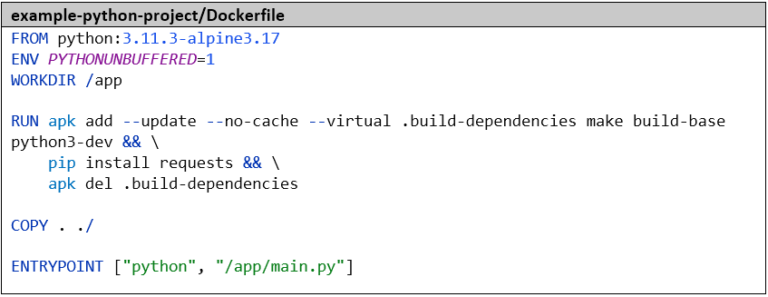
Die Anwendung packen wir dann wieder in ein Docker Image. Die Umgebungsvariable PYTHONUNBUFFERED=1 ist wichtig um sicherzustellen, dass wir die Log-Ausgaben in Echtzeit sehen können. Die Abhängigkeiten – in diesem Fall nur eine Bibliothek, ansonsten würden wir eine requirements-Datei verwenden – installieren wir mit pip.
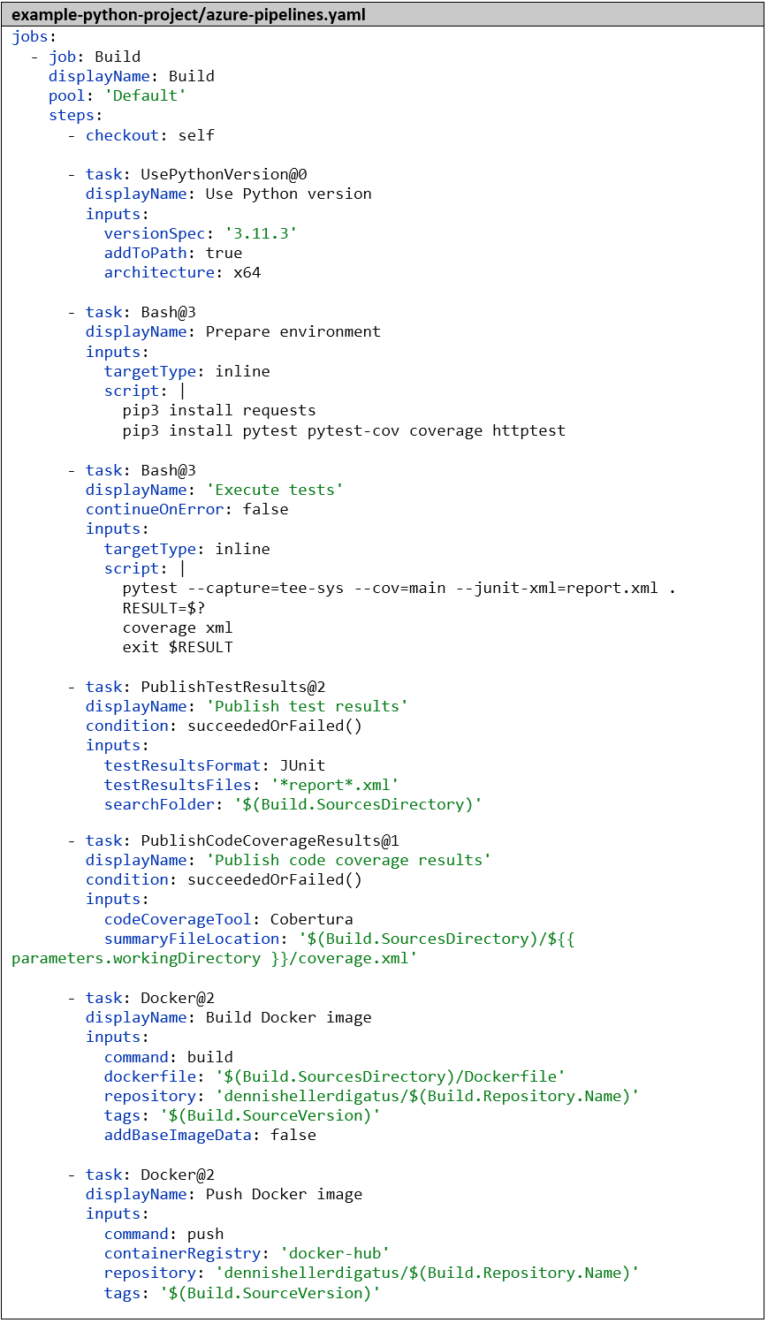
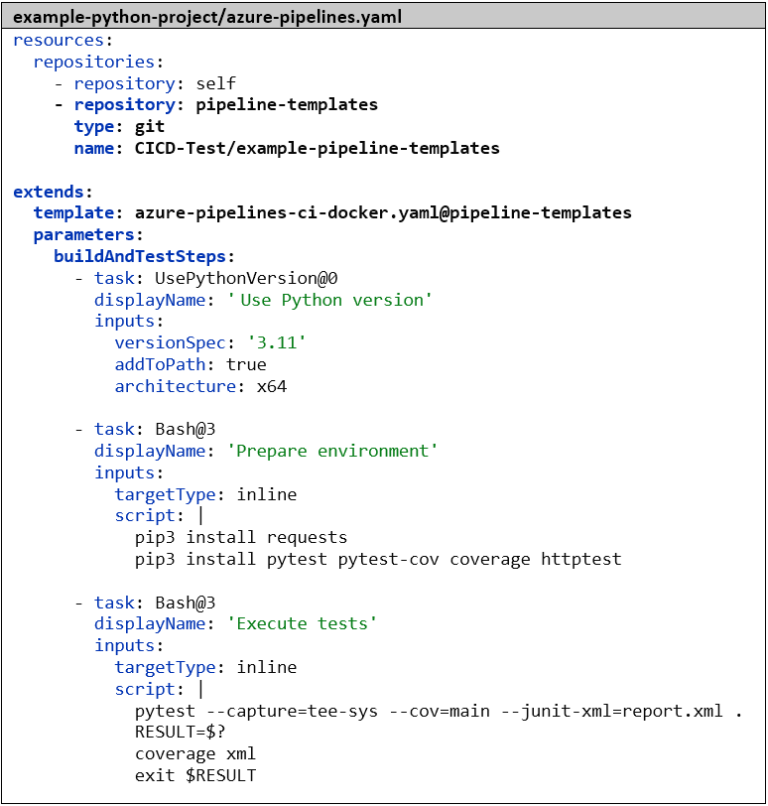
Die Pipeline erstellen wir analog zur Go-Pipeline. Als ersten Step teilen wir Azure DevOps wieder mit, mit welcher Sprache und welcher Version wir arbeiten wollen – in diesem Fall mit Python 3.11.3. Als nächstes installieren wir die Abhängigkeiten und danach führen wir die Tests mit pytest aus. Der Parameter –capture=tee-sys sorgt dafür, dass wir im Test die Standardausgabe abfangen können. Mittels –cov=main lassen wir die Code Coverage berechnen und mit –junit-xml=report.xml erzeugen wir den klassischen Test-Bericht. Auch hier gibt es bereits ein Tool zum Aufbereiten der Code Coverage: das Python-Package coverage. Ohne weitere Parameter ist es standardmäßig mit dem Ergebnis-Format von pytest kompatibel. Die restlichen Steps zum Veröffentlichen der Test-Ergebnisse und zum Bauen und Pushen des Docker Images sind identisch mit der Go-Pipeline:
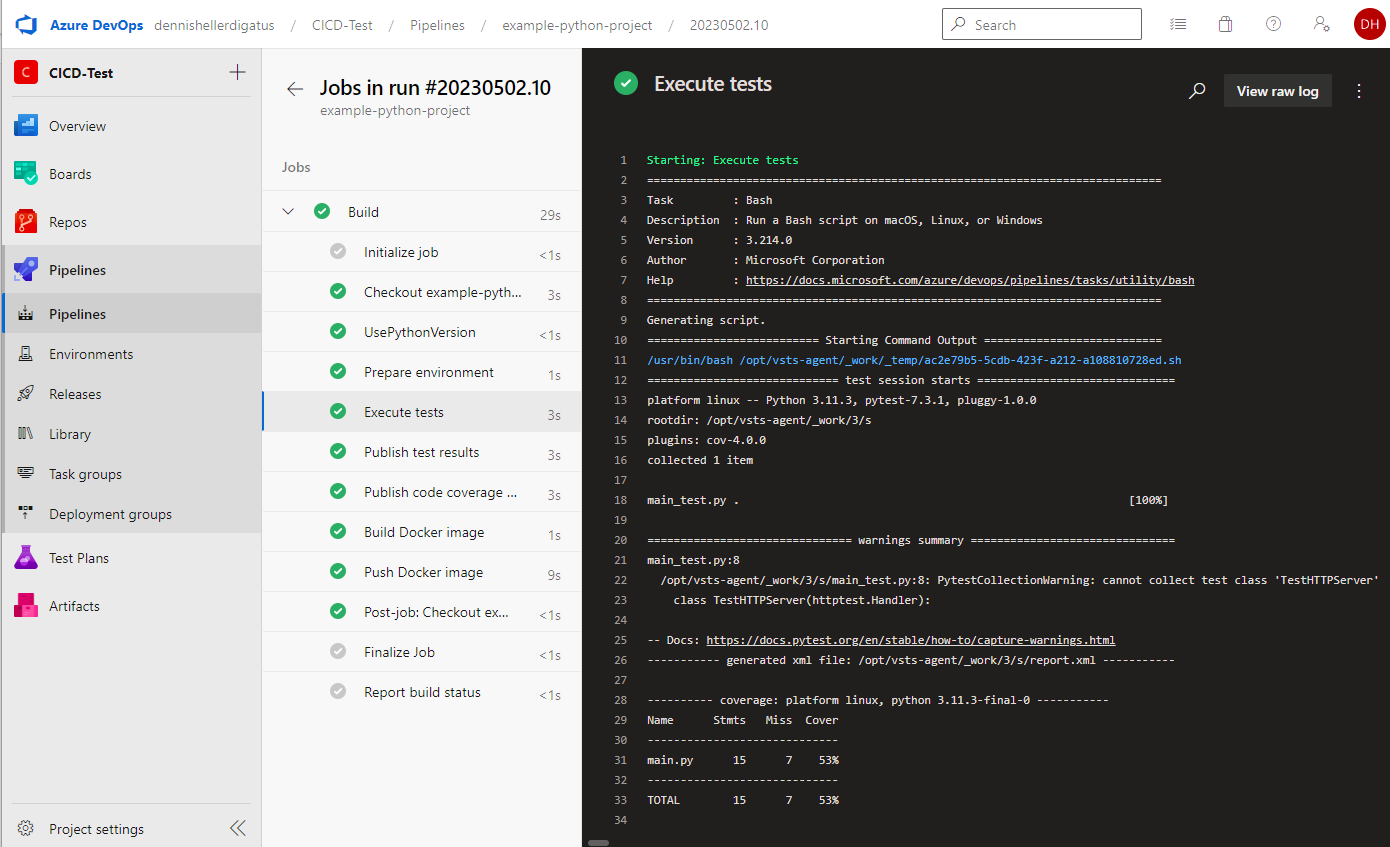
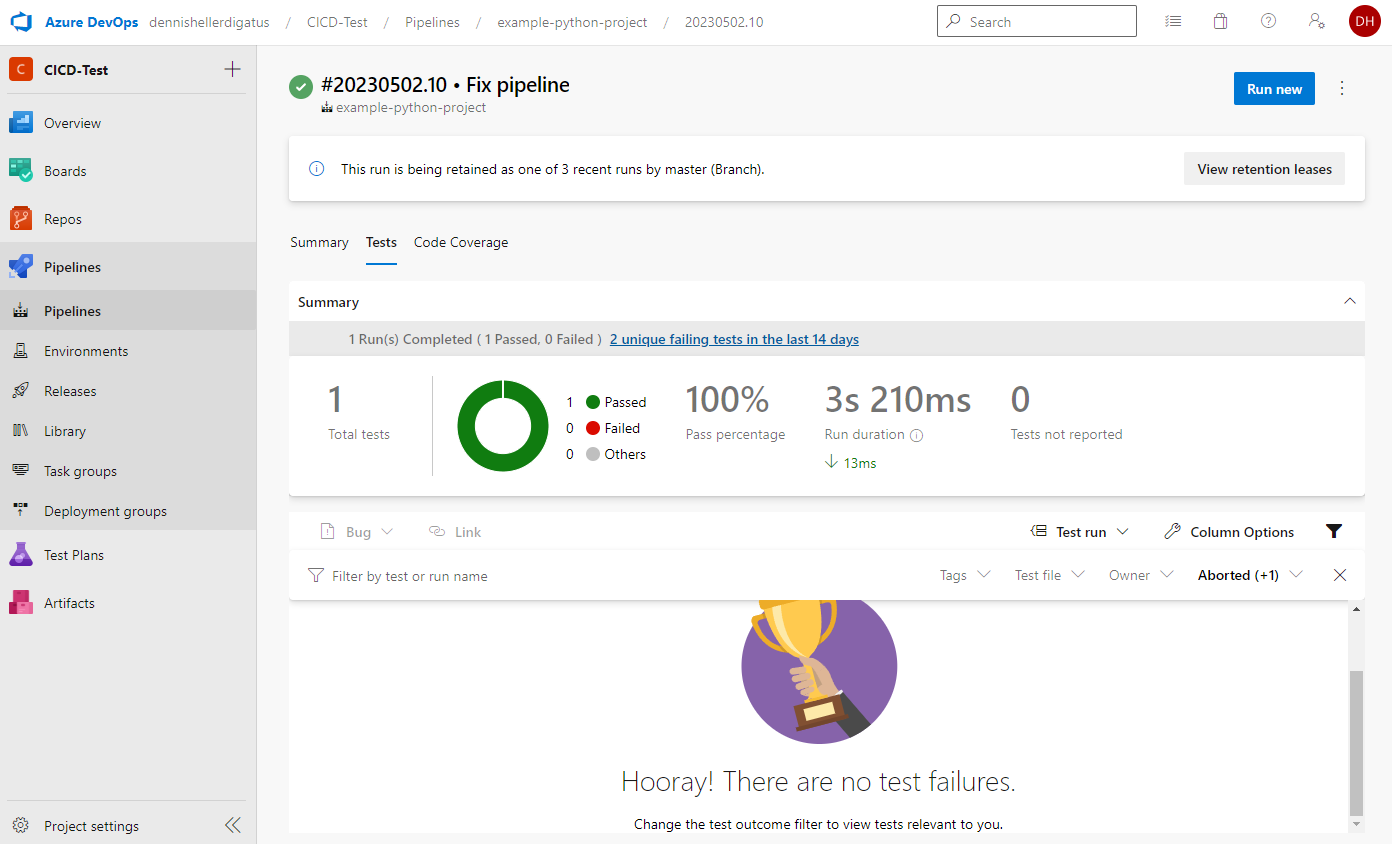
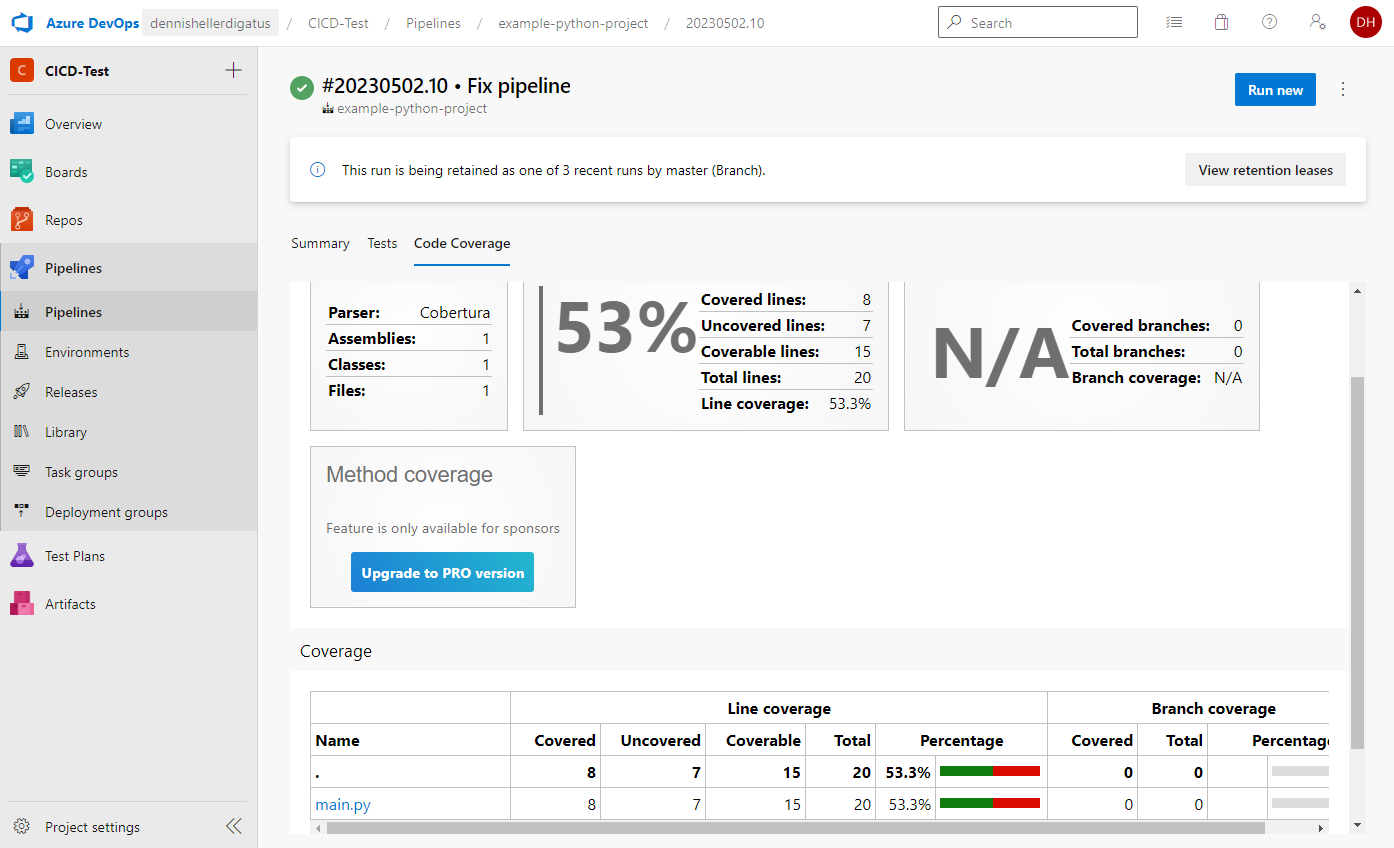
Fertig ist unsere erste Python-Pipeline. Das Ergebnis kann sich sehen lassen:
Ebenso die Test Ergebnisse und die Coverage:
Vorrausschauend denken: Pipeline-Templates
Wenn wir nun unsere beiden Pipelines – Go und Python – miteinander vergleichen, stellen wir fest, dass wir einige identische und einige unterschiedliche Steps haben. Um bei zukünftigen Pipelines Arbeit zu sparen, bietet uns Azure DevOps die Möglichkeit an, Pipeline-Templates zu erstellen. Auch, falls wir später einen gemeinsamen Teil der Pipeline ändern oder erweitern wollen, müssen wir dies dann nur einmal im gemeinsamen Template tun und nicht in jeder einzelnen Pipeline.
Die Template-Hierarchie ließe sich sogar weiter fortführen, sodass wir z.B. ein gemeinsames Template für das gesamte Unternehmen hätten, dann ein Unter-Template für das Projekt und weitere Unter-Templates für CI und CD, verschiedene Sprachen und Frameworks bis zur finalen Pipeline für einen Microservice. Das Schlüsselwort zum Verwenden von Templates lautet wie in der objekt-orientierten Programmierung extends:. Wichtig ist: eine Pipeline kann nur von genau einem Template erben. Der Schlüssel um Templates erweiterbar zu machen, sind Parameter, mit denen sich die Platzhalter im Template füllen lassen. Diese Parameter können einfache Textwerte, Zahlen, Listen, komplexe Objekte und sogar Listen von kompletten Pipeline-Steps sein. Default-Werte sind ebenso möglich. Die Parameter eines Template werden ganz oben im Template unter dem Abschnitt parameters: deklariert und können dann im Code des Templates mit der folgenden Notation verwendet werden: {{ parameters.xxx }}. Die Template-Hierarchie und die Parameter werden beim Kompilieren der Pipeline ausgewertet, um ein einziges großes Pipeline-Skript zu erstellen, in dem die Parameter bereits ersetzt sind. Im Gegensatz zu den Parametern gibt es sogenannte Variablen, die zur Laufzeit erstellt, verändert und ausgelesen werden können. Diese werden mit der folgenden Notation verwendet und erst zur Laufzeit interpretiert: $(variable). Template-Dateien werden wie normale Pipelines als YAML-Dateien gespeichert. Da sie in mehreren anderen Git-Repositories verwendet werden, bietet es sich an, ein eigenes Git-Repository für sie zu erstellen, in unserem Fall nennen wir es example-pipeline-templates.
Zurück zu unseren beiden Pipelines: die Grundstruktur (das Veröffentlichen der Test-Ergebnisse und das Bauen und Hochladen des Docker Images) ist identisch. Nur der mittlere Teil, das Bauen und Testen unterscheidet sich. Hier eine Übersicht über alle Steps der beiden Pipelines:
Es bietet sich also an, den checkout: Step und die letzten 4 Steps in ein gemeinsames Template zu verschieben und für den mittleren Teil einen Platzhalter mit Parameter einzusetzen. Das sieht wie folgt aus:
Falls ein Parameter als einzelner YAML-Listen-Eintrag notiert wird, aber eine Liste enthält, expandiert Azure DevOps diese automatisch, ohne dass wir hier extra eine each-Schleife schreiben müssen. Das Template sieht im Prinzip aus wie eine normale Pipeline und könnte auch als solche verwendet werden. Wenn wir in Azure DevOps eine Pipeline mit dieser Template-Datei anlegen würden, müssten wir beim Starten der Pipeline die Parameter von Hand füllen, was für den Typ stepList nicht möglich ist. Deshalb würde hier der Default-Wert genommen werden: eine leere Liste.
Wir ändern nun unsere beiden bisherigen Pipelines, sodass sie von diesem Template erben und setzen dabei die Werte für die Parameter. Dazu müssen wir zuerst das Git-Repository angeben, das das Template enthält und es mit einem Alias benennen. Danach können wir mit extends: und template: das Template angeben. Die Syntax lautet hier <relativer Pfad>@<repository-Alias>. Wenn eine Pipeline extends: auf oberster Ebene enthält, darf sie nicht daneben noch eigene stages:, jobs: oder steps: enthalten, sondern die komplette Pipeline muss über das Grundgerüst des Templates gebaut sein und alle individuellen Änderungen müssen über Parameter realisiert werden. Wie bereits erwähnt, bastelt Azure DevOps vor dem Ausführen der Pipeline aus der Template-Hierarchie ein einziges großes Pipeline-Skript zusammen, sodass wir am Ende exakt das gleiche Ergebnis zu sehen bekommen.
Versionierung mit Git Tags
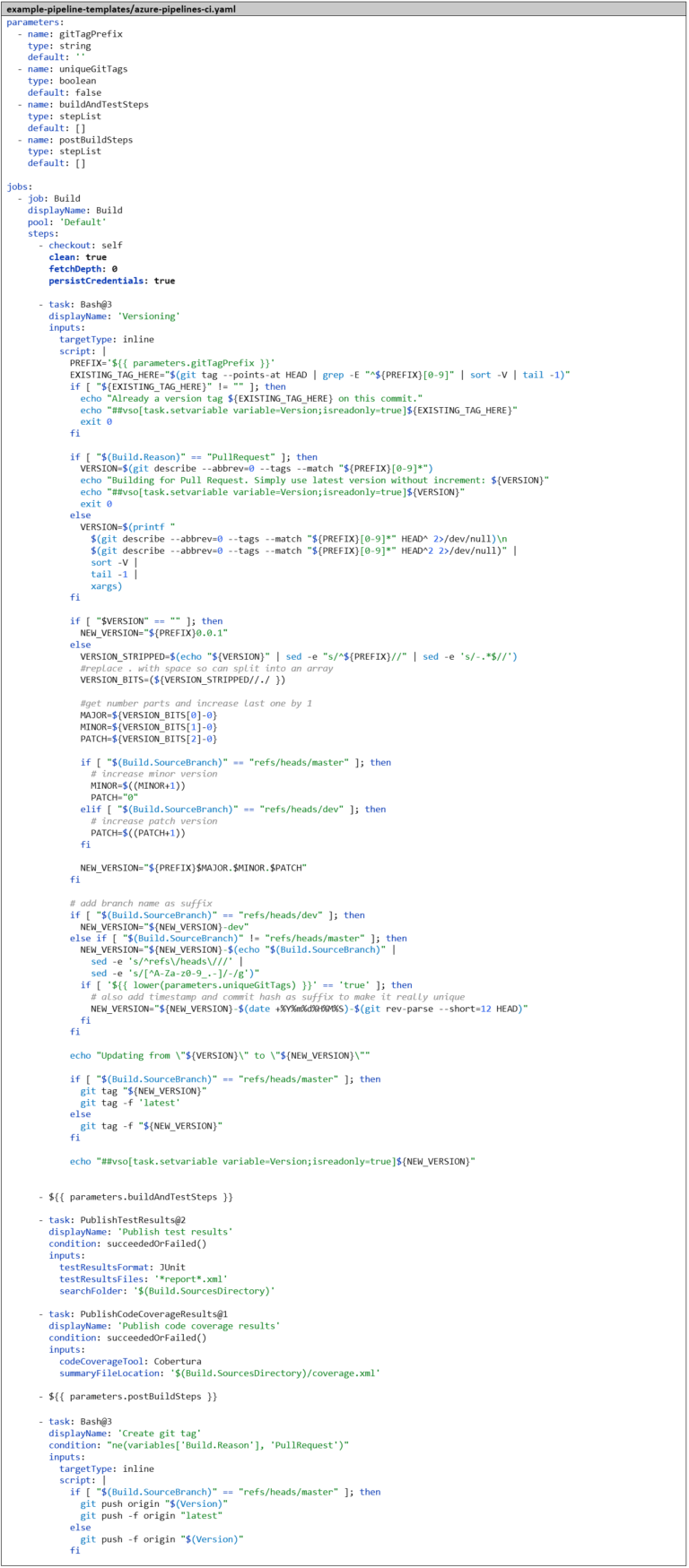
Momentan verwenden wir den Git Commit-Hash als Docker Image Tag, welcher schwer zu merken ist. Ein hart-codierter Tag wie latest hätte den Nachteil, dass wir immer nur eine Version parallel verwenden könnten. Es macht also Sinn, ein Versionierungs-Konzept auf Basis von Semantic Versioning einzuführen und dieses in die Pipeline zu integrieren, sodass die Versionsnummer automatisch hochgezählt und gleichzeitig als Docker Image Tag verwendet wird. Außerdem erstellen wir bei jedem Build ein Git Tag, um später die Docker Images dem Source-Code zuordnen zu können. Da die Logik hierfür relativ komplex wird, packen wir sie in ein Bash-Skript. Höchstwahrscheinlich werden wir sie in zukünftigen CI-Pipelines ebenfalls brauchen, deshalb erstellen wir gleich ein weiteres Template azure-pipelines-ci.yaml, das als neues Basis-Template für azure-pipelines-ci-docker.yaml dient. Somit haben wir schon eine Template-Hierarchie mit drei Ebenen.
Zur Erklärung des Skriptes – wir unterscheiden verschiedene Fälle:
Wenn direkt auf dem Commit, für den die Pipeline läuft, schon ein Versions-Tag ist, nehmen wir diesen und ändern nichts an der Version.
Wurde die Pipeline aus einem Pull Request heraus gestartet, ist uns die Versionierung egal. Wir wollen nur herausfinden, ob der Code und das Docker Image gebaut werden können und ob die Tests erfolgreich sind. Also nehmen wir einfach die letzte bisherige Version, die wir in der Git-Historie finden können und ändern nichts an der Version.
Ansonsten suchen wir in der Git-Historie in der Vergangenheit den am nächsten liegenden Versions-Tag. Falls wir auf einem Merge-Commit sind, suchen wir in beide Richtungen und nehmen die höhere Version.
Falls wir keine bisherige Version finden, starten wir mit der Version 0.1.
Ansonsten erhöhen wir die Version wie folgt:
Auf dem master-Branch erhöhen wir die Minor Version um 1.
Auf dem dev-Branch erhöhen wir den Patch-Level um 1.
Auf Feature-Branches erhöhen wir die Versionsnummer nicht.
Außerdem hängen wir ein Suffix an die Versionsnummer:
Auf dem dev-Branch -dev.
Auf Feature-Branches eine abgespeckte Variante des Branch-Namens.
Bei Go-Projekten ist es wichtig, dass die Tags nicht verschoben werden, da der Go-Client das komplette Git-Repository lokal cacht und zu jeder Version eine Signatur speichert, die sich nicht mehr ändern darf. Für diesen Anwendungsfall gibt es den Parameter uniqueGitTags. Wenn dieser auf true gesetzt ist, erstellen wir für jeden Commit eine eigene eindeutige Version, indem wir einen weiteren Suffix anhängen, der den Commit-Hash und einen Zeitstempel enthält.
Aus dem Bash-Skript heraus erstellen wir eine Laufzeit-Pipeline-Variable namens Version. Das ist möglich mit Hilfe eines sogenannten Logging-Commands. Dazu müssen wir nur einen speziellen Befehl in die Standard-Ausgabe des Bash-Skriptes schreiben: echo„##vso[task.setvariable variable=<NAME>;isreadonly=true]<WERT>“. So kann die Version in den darauffolgenden Pipeline-Steps verwendet werden, zum Beispiel als Docker Image Tag. Nur wenn die Pipeline erfolgreich durchgelaufen ist, pushen wir den Versions-Tag zurück ins Remote-Git-Repository, ansonsten soll er ignoriert werden. Dazu zwingen wir Azure DevOps bei jeder Ausführung einer Pipeline das Git-Repository komplett clean auschecken, indem wir im checkout: -Step den Parameter clean: true setzen. Außerdem müssen wir noch den Parameter persistCredentials: true setzen, ansonsten würden nach dem checkout: -Step die Zugangsdaten fürs Remote-Git-Repository aus Sicherheitsgründen gelöscht werden und wir hätten keine Zugangsdaten um den Git-Tag zurück zu pushen.
Die azure-pipeline-ci-docker.yaml verkürzt sich dann auf die beiden Docker-Steps. Für die Referenzierung des Templates reicht hier der Dateiname azure-pipeline-ci.yaml aus, da sich beide Dateien im selben Git-Repository befinden. Wichtig ist hier jetzt natürlich noch die Änderung des Docker Image Tags von ‚$(Build.SourceVersion)‘ zu ‚$(Version)‘., um die Versionsnummer als Docker Image Tag zu verwenden. Falls wir auf dem master-Branch sind, setzen wir – wie bei Docker Images üblich – neben der Versionsnummer noch den latest-Tag. Außerdem fügen wir beim „Push Docker Image“–Step eine condition: hinzu, die den Step im Kontext eines Pull Requests überspringen lässt. Ebenso wie bei der Versionierung sind wir im Kontext eines Pull Requests nämlich nur daran interessiert, die Validität des Codes zu prüfen und nicht irgendetwas zu veröffentlichen.
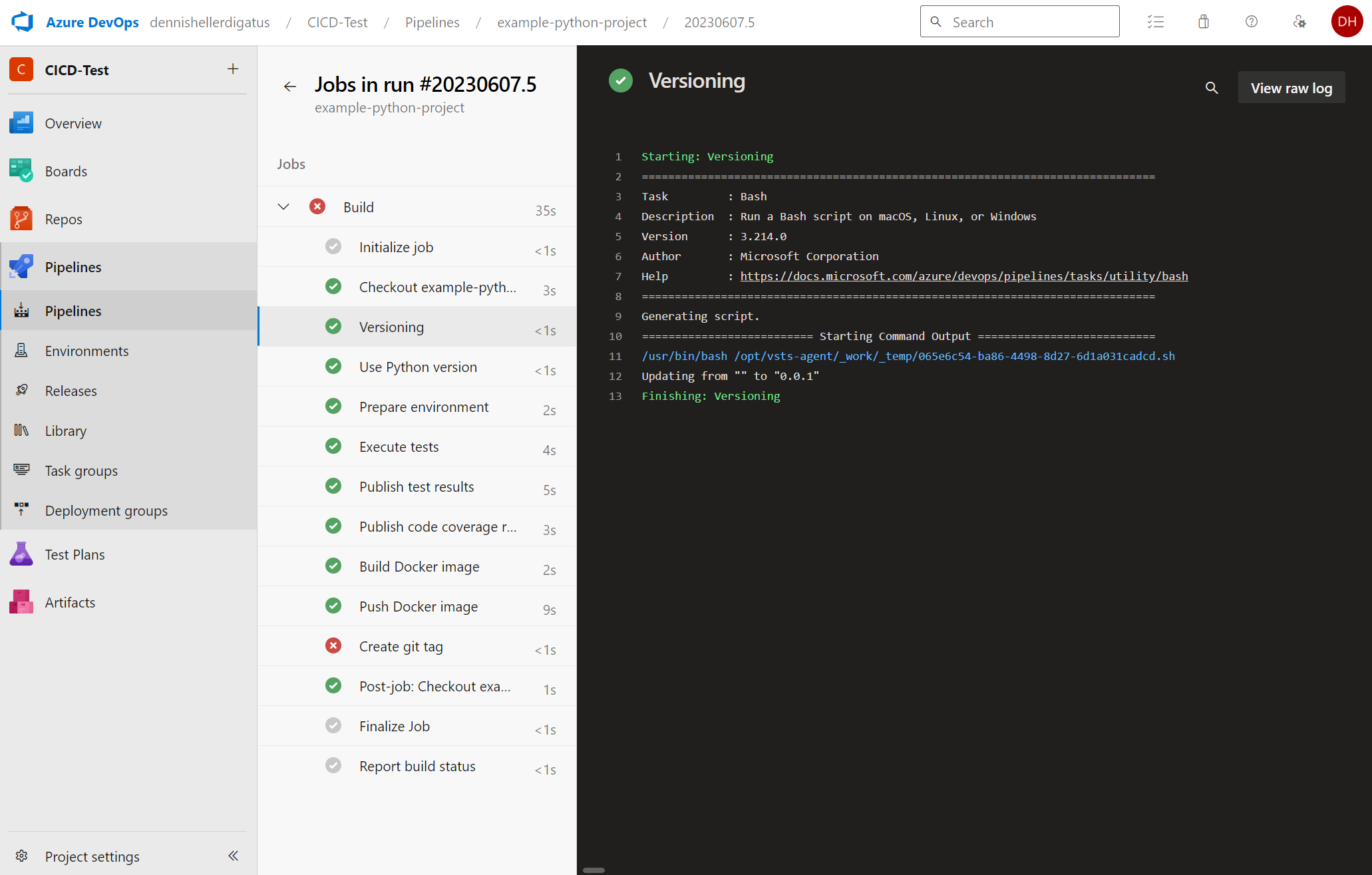
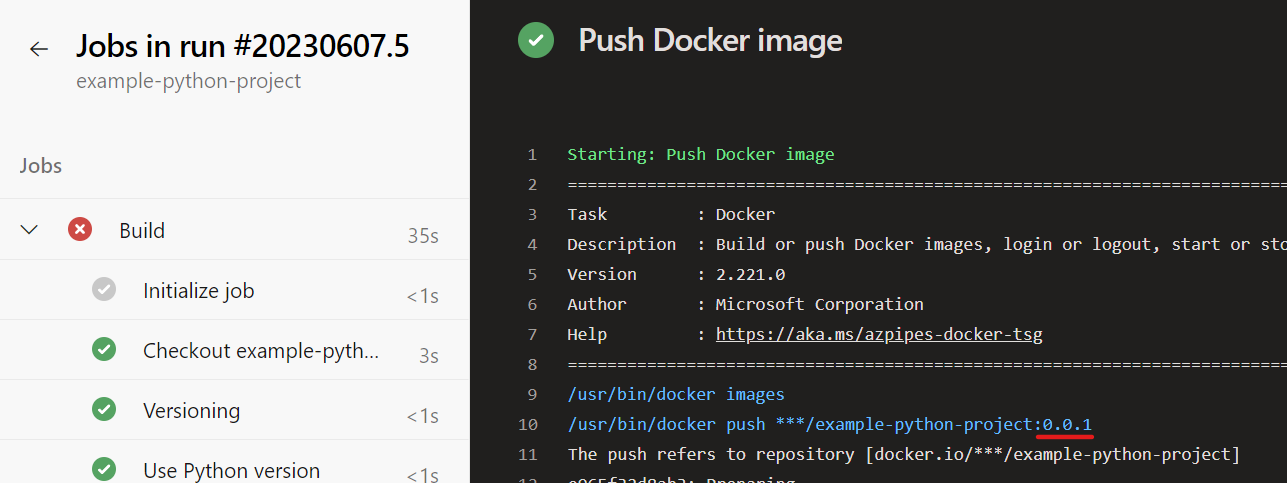
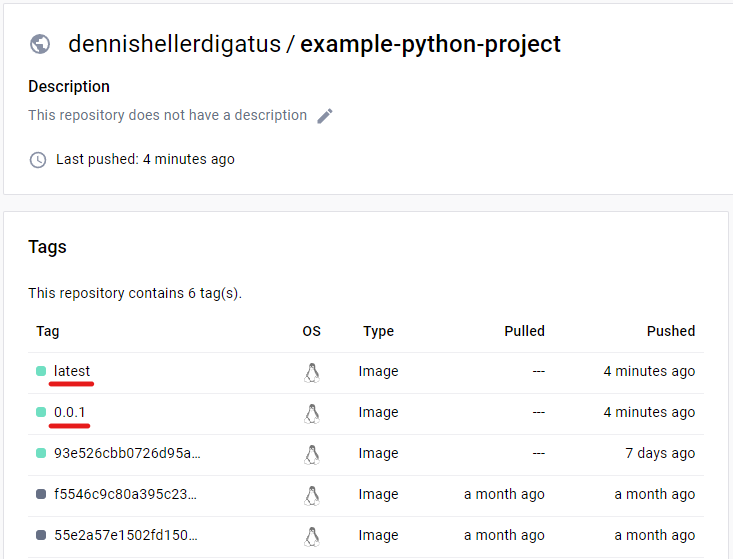
Nun starten wir die Pipeline fürs example-python-project. Von dem großen Umbau hinter den Kulissen ist erstmal nicht viel zu sehen. Neu sind die Build-Steps Versioning und Create git tag. Da wir bisher keinen anderen Versions-Tag haben, bekommen wir die folgende Meldung: Updating from „“ to „0.0.1“.
Beim Docker Push wird jetzt wie gewünscht die Versionsnummer als Tag verwendet:
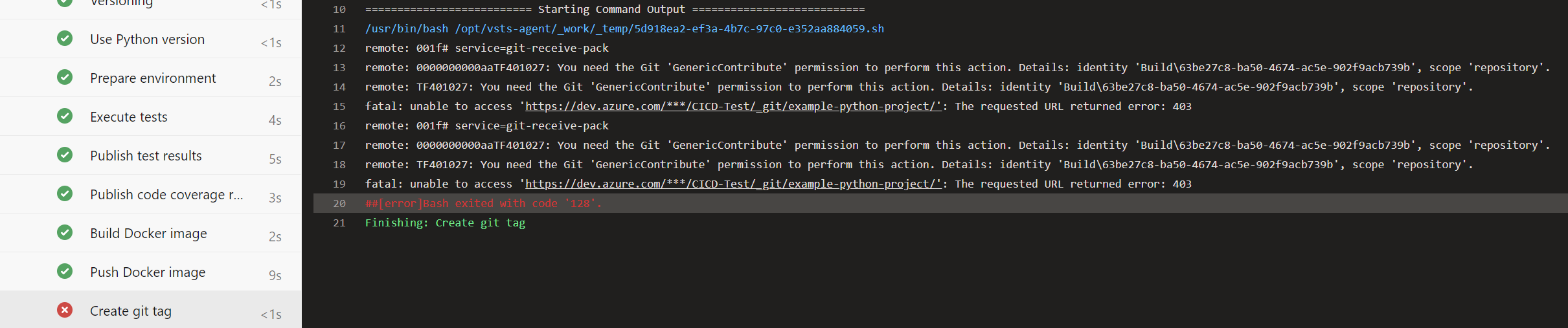
Leider schlägt das pushen des Git Tags noch fehl:
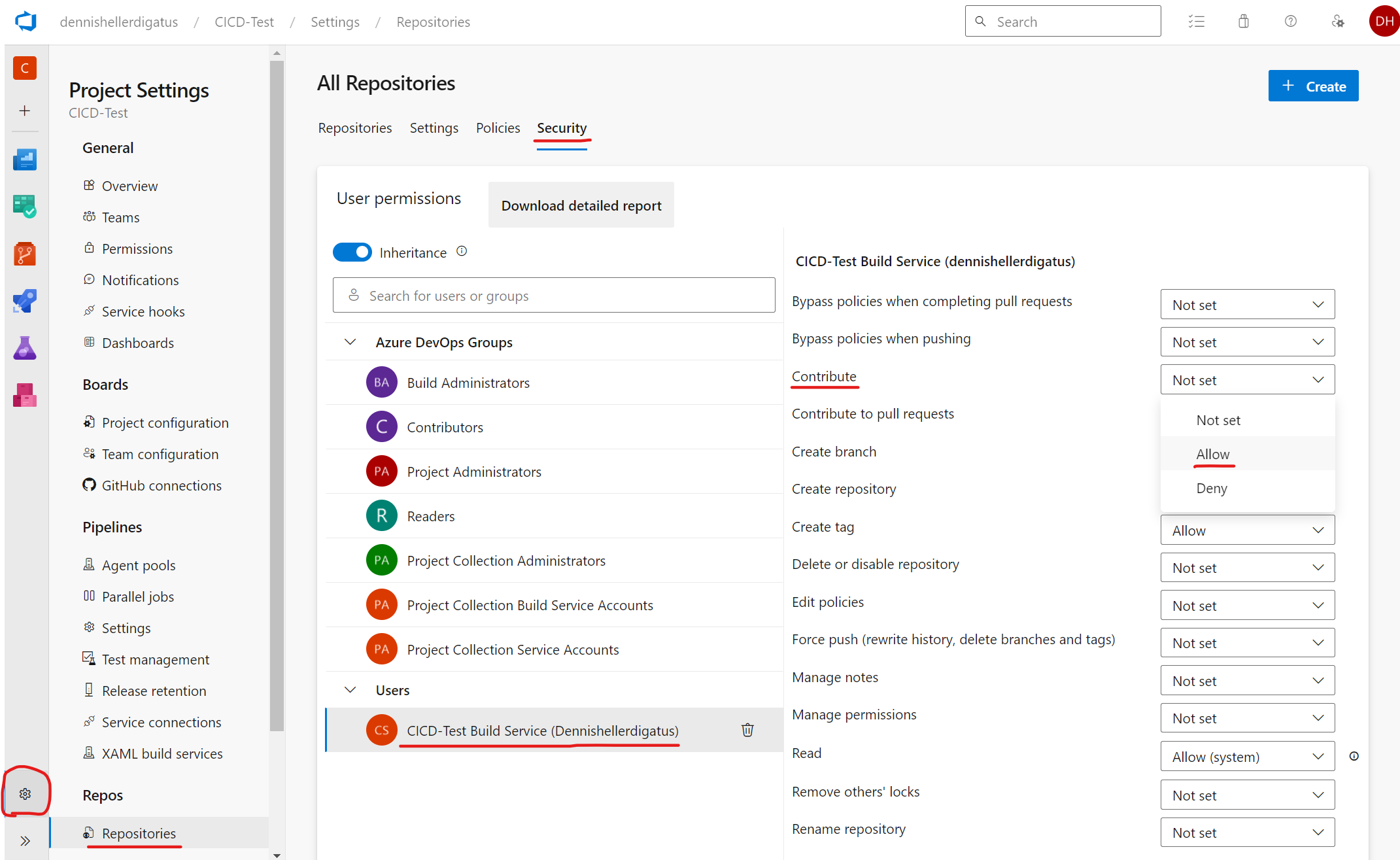
Das liegt daran, dass Pipelines in Azure DevOps im Namen eines virtuellen Benutzers namens <Projekt-Name> Build Service (<Organisations-Name>) ausgeführt werden. Dieser hat aus Sicherheitsgründen standardmäßig keine Schreibrechte auf den Git-Repositories. In unserem Fall ist das aber erwünscht. Um die nötige Berechtigung zu erteilen, hangeln wir uns über das Zahnrad unten links durchs Menü zu „Project Settings“ à „Repositories“ à Reiter „Security“ à „Users“ à „CICD-Test Build Service (dennishellerdigatus)“ und ändern in der Tabelle rechts den Wert bei Contribute von Not Set auf Allow:
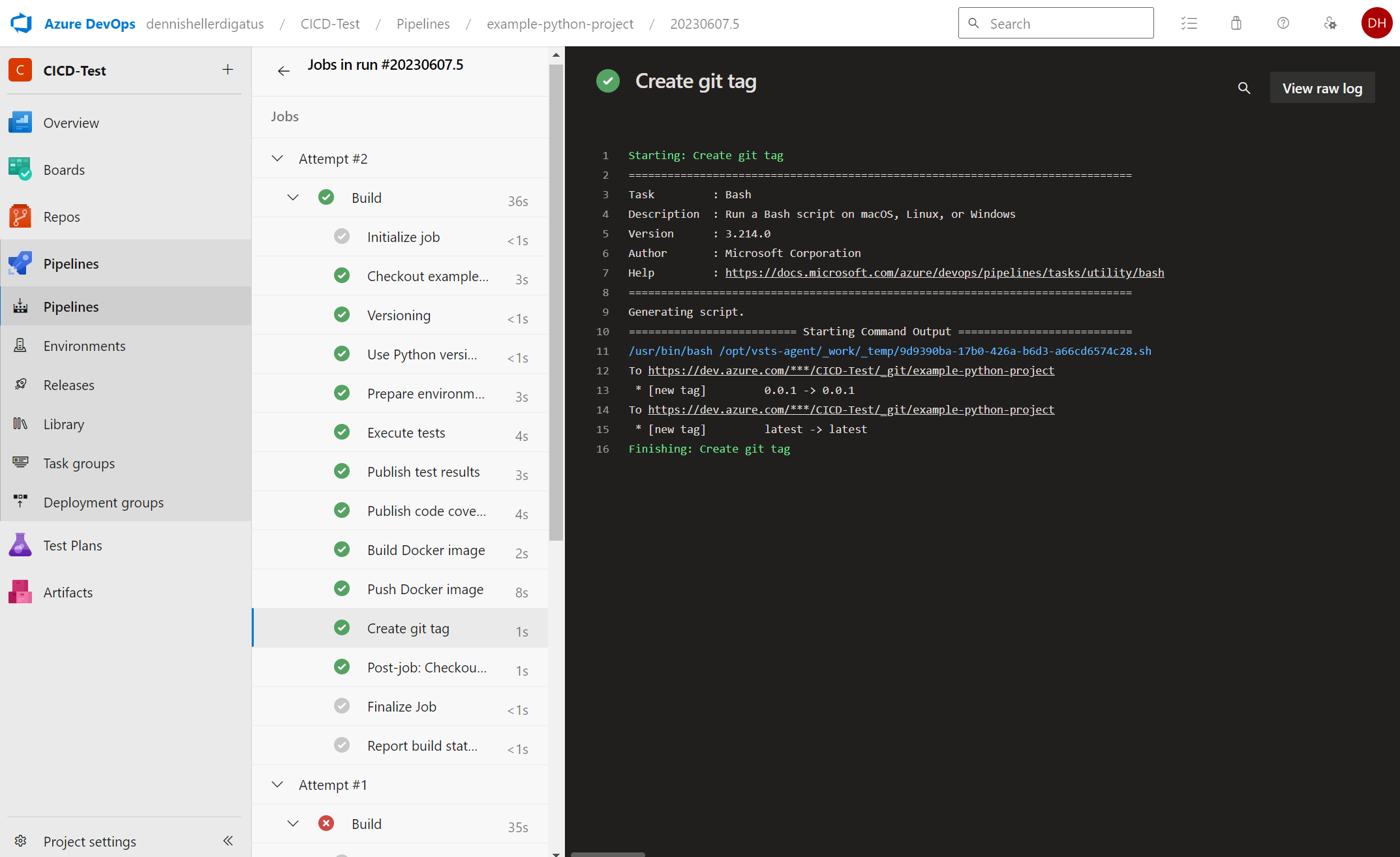
Ein Klick auf Rerun failed jobs in der fehlgeschlagenen Pipeline zeigt uns, dass wir die richtige Einstellung im Berechtigungs-Dschungel von Azure DevOps erwischt haben. Die Pipeline läuft jetzt erfolgreich durch:
Ebenfalls sehen wir im Git Log und im Docker Hub die neuen Tags:
Fazit
Azure DevOps bietet eine Vielzahl an Möglichkeiten, sowohl einfache als auch komplexe Pipelines zu erstellen. Schön ist, dass man – im Gegensatz zu anderen CI/CD-Systemen – schnell und einfache Pipelines erstellen kann, ohne sich um viele Themen Gedanken machen zu müssen. Das liegt daran, dass die Standard-Werte und -Einstellungen zwischen der nötigen Freiheit und Sicherheit sehr gut ausbalanciert sind. Die komplexeren Features sind so verkapselt, dass sie nicht stören, wenn man sie nicht braucht. Später kann man Stück für Stück aus diesen Rahmen ausbrechen, wodurch man zwar mehr Code selber schreiben und Einstellungen ändern muss, aber auch mehr Features zur Verfügung hat. So lassen sich mit Template-Hierarchien und Bash-Skripten auch komplexe Szenarien umsetzen.
Die Wiederverwendbarkeit und Erweiterbarkeit von Pipeline-Skripten durch die Template-Funktion – vor allem das Einfügen von ganzen Step-Listen – ist definitiv eine der großen Stärken von Azure DevOps. Und falls die Standard-Tasks nicht ausreichen, gibt es jederzeit die Option, auf die umfangreichere Bash-Ebene zu wechseln. Dort sind ebenfalls alle nötigen Tools installiert, wie git, go und python. Falls wir einen selbst-gehosteten Build-Agent verwenden, könnten wir beliebige weitere Tools installieren wie zum Beispiel jq, make oder kustomize. Um Berechtigungen mussten wir uns bisher zum Glück fast gar nicht kümmern. Hier gibt es auch sehr viele Möglichkeiten zur Konfiguration, nur leider ist die Wirkungsweise der Berechtigungen teilweise sehr schwer nachzuvollziehen. Ein Pluspunkt hier ist jedoch, dass Azure DevOps für häufig vorkommende Berechtigungsprobleme einen „Quick-Fix“-Button anbietet, der an Ort und Stelle automatisch die Berechtigungen anpasst, ohne dass man sich durch komplexe Menüs durchhangeln muss.
Letzte Beiträge
IT Security
Die digatus technology GmbH ist erfolgreich nach ISO/IEC 27001 zertifiziert
Digitalisierung, IT M&A
IT- und OT-Integration im Rahmen von Akquisitionsprozessen
IT Carve-Out, IT M&A
Erfolgreicher IT-Carve-out bei Trench: Von der Konzernstruktur zum mittelständischen Marktführer